2022. 6. 3. 14:31ㆍMajor`/정보보호개론
Access Control Matrix
인가는 "인증된 user"에게 어디까지 권한을 줄지에 관한 것이다
대표적으로 "인증된 user에 대한 시스템 자원의 권한"을 Matrix 형태로 나타낸다

row는 인증된 user로써 사람이 될 수도 있고, 시스템 상의 자원이 될 수도 있다
column은 시스템 상의 자원을 나타낸다
Bob을 보면 OS에 대한 "rx"권한이 존재하고 Accounting Program에 대해서도 "rx"권한이 존재하고 Accounting Data에 대해서는 "r"권한이 존재한다
- r : read
- w : write
- x : execute
하지만 이러한 Matrix방식은 "user - Resource"가 많아질수록 크기가 굉장히 커진다
이러한 Matrix를 2가지 측면에서 나눈 "Access Control Lists(ACL) & C-List"라는 것이 존재한다
Access Control List(ACL) vs Capabilities(C-List)


▶ ACLs
(Bob, ---) (Alice, rw) (Sam, rw) (Accouting Program, rw)
(user, <권한>)형식으로 각 자원마다 관리가 된다
user가 자원에 접근할 때마다 "user가 올바르게 접근하는지" 매번 check한다
▶ C-List
(OS, rx) (Accounting Program, rx) (Accounting Data, r) (Insurance Data, rw) (Payroll Data, rw)
(자원, <권한>)형식으로 관리가 된다
user가 어떤 자원에 대해서 특정 권한으로 접근하면 "자원 입장에서 이사람이 가지고있는 권한으로 접근하는건지" 매번 check한다

ACLs와 C-List는 "화살표 방향"이 다르다. 물론 그림상에서는 별 차이가 없겠지만 실질적으로 "보안"의 측면에서 봤을 때는 엄청난 차이가 존재한다
C-List가 ACLs에 비해서 보안측면에서 몇가지 장점을 가지고 있다
Confused Deputy

이러한 시스템상의 Matrix가 존재한다고 하자
Alice는 Compiler에 대한 실행권한만 있을 뿐, Bill에 대한 권한은 아무것도 없다
반면에 Compiler는 Bill에 대한 "rw"'권한이 존재한다
여기서 알수있는 사실은 "Alice는 Bill에 직접 접근할 수 없다"라는 사실이다
그러면 영원히 접근할 수 없을까??

1. Alice가 어떤 프로그램에 Bill에 접근하는 코드를 작성
2. Compiler를 통해서 해당 프로그램 실행
>> 결국 Compiler에 의해서 Bill에 접근 성공
Alice는 Compiler를 통해서 Bill에 간접적으로 접근을 성공했다
Complier는 "Alice의 Bill 접근 행동"을 대신 수행해주었다
>> Compiler는 혼란이 온다
- 분명 Alice는 Bill에 대한 권한이 없었는데 "나"를 이용해서 Bill에 대해서 접근을 했다. "나(컴파일러)"는 Alice에 의해서 동작하는데 어떻게 나의 권한을 이용해서 Bill에 접근했을까
ALCs를 사용하면 Confused Defuty를 피하기 힘들지만 반면에 C-List를 사용하면 Confused Defuty를 손쉽게 해결할 수 있다
이 둘의 큰 차이점은 "위임 가능"이다
ACLs는 (user, <권한>)으로 관리가 되기 때문에 user간에 권한을 위임하려면 시스템 자체를 바꿔야 해야 하기 떄문에 위임이 굉장히 힘들다
반면에 C-List는 (자원, <권한>)으로 관리가 되기 때문에 user간에 권한 위임이 손쉽게 이루어진다
따라서 위의 예시의 경우 C-List를 사용하면 Alice의 (Bill, ---)을 Compiler에게 위임함으로써 Complier는 Bill에 대한 접근이 불가능하게 된다
이렇게 C-List를 사용하면 Confused Defuty를 해결할 수 있다
Covert Channel
Cover Channel이란 시스템 설계자가 의도하지 않은, 생각조차 못한 통신통로를 의미한다
시스템 설계자는 (A-B) (B-C) (C-D) 순으로 통신 통로를 설계했다고 하자
근데 공격자가 어떤 시도 끝에 (A-C)로 다이렉트로 가는 통로를 발견했다고 하자
>> (A-C)같은 시스템 설계자가 의도하지 않은 통신통로를 "Covert Channel"이라고 한다
근데 시스템 설계자가 이러한 Covert Channel을 제거한다는 것은 사실상 불가능하기 때문에 Covert Channel를 통해서 최대한 정보가 빠져나가지 않도록 설계하는 것이 중요하다
Example)
Alice는 보안 등급 (1)을 보유한 user이고, Bob은 보안 등급 (3)을 보유한 user이다
따라서 Alice는 모든 기밀문서에 접근할 수 있고 반면에 Bob은 일반 문서에만 접근할 수 있다
>> 여기서 Covert Channel을 사용하면 BLP 제약인 "상향 읽기 금지, 하향 쓰기 금지"를 위빈할 수 있다
Bob은 호기심이 생겨서 Alice에게 나도 기밀 문서에 접근하고 싶다라고 의견을 표명했다. 하지만 실질적으로 불가능한 일이기 때문에 Alice는 Covert Channel을 이용해서 "기밀 문서에 접근은 못하겠지만, 어떤 기밀 문서가 있는지 알려줄게"라고 했다
Alice가 1을 보냄 : 특정 파일 생성
Alice가 0을 보냄 : 특정 파일 삭제
Bob이 1을 보냄 : 특정 파일의 존재가 확인
Bob이 0을 보냄 : 특정 파일이 없음
이런식으로 bit를 서로 교환함으로써 특정 파일이 존재하는지 여부를 Bob이 파악할 수 있을 것이다

Covert Channel의 존재 조건
1) {Sender & Receiver} 모두 공유된 자원에 대한 접근 권한을 가지고 있어야 한다
2) Sender는 Receiver가 "관찰"가능한 공유 자원에 대한 write를 할 수 있어야 한다
3) {Sender & Receiver} 간의 sync를 맞춰야 한다
Covert Channel With TCP
실세계에서 Covert Channel을 사용하는 예시는 TCP에 있다
TCP Header에는 어떠한 값도 지정되지 않은 "reserved field"가 존재한다
이 reserved field를 Covert Channel 역할을 수행하게 함으로써 정보를 은닉시켜서 통과하게 할 수 있다

아니면 Sequence Number나 Flag(ACK)에 정보를 은닉해서 Covert Channel을 생성할 수도 있다
Data를 Sequence Number에 은닉한다고 가정하자

정상적인 통신이라면 A는 {Source : A / Dest : B}로 TCP Header를 설정해서 패킷을 보냈을 것이다
하지만 {A-C}간의 Covert Channel을 위해서 A는 {Source : C / Dest : B}로 패킷을 보내었다
이 패킷을 받은 Server(B) 입장에서는 "Source가 C로부터 왔으니까 응답 패킷을 C로 보내야겠다"라고 생각해서 ACK를 C로 보내게 되었다
여기서 A가 B로 보낸 Sequence Number(X)는 B가 C로 응답을 할때 ACK에 포함되어서 응답된다
따라서 {A-C}는 Server(B)를 통해서 X라는 데이터를 Sequence Number & ACK에 은닉해서 잘 교환한 것을 확인할 수 있다
Inference Control
Inference Control이란 "추론 제어"를 의미한다
Example)
어떤 대학의 컴퓨터공학부 교수 현황을 보니까 {남 : 20, 여 : 1}로 구성되어 있다고 하자
여기서 user가 해당 학과 DB로 "SELECT AVG(SAL) FROM CS"라고 query를 날렸다고 하자
그리고 해당 쿼리에 대한 응답으로 "$95000"이라는 응답을 받았다
이후 동일한 DB상에 "SELECT COUNT(*) FROM CS WHERE GENDER="FEMALE"이라는 query를 날렸다
여기서 해당 쿼리에 대한 응답으로 "1"을 받았다고 하자
그러면 해당 학과에 "여자 교수"가 1명이라는 의미이다
이처럼 특정 정보가 일반적인 질의에 대한 응답으로 누출되는 경우를 방지하기 위해서 "Inference Control"을 사용하게 된다
추론 제어 기법
1) 질의의 크기 제어
질의의 크기 제어란, 질의 결과가 너무 적을 경우 해당 질의는 무시하는 것이다
하지만 이렇게 질의의 크기를 제어한다고 했을 경우, 생기는 문제점은 "의학"쪽에서 발생할 수 있다
굉장히 희귀한 질병을 연구하는 의사의 입장에서 질의의 크기를 제어한다는 것은 해당 연구를 원활하게 진행할 수 없다는 의미이다
2) N-응답, K% 지배
N명 이하에 대해서 제공되는 데이터가 k%이상이면 공개하지 않는 방식이다
예를 들어서, 빌 게이츠가 사는 동네의 평균 연봉을 조사하면 사실상 빌게이츠의 연봉이 99.9999...%를 차지하게 될 것이다
이러한 경우 제공되는 데이터를 공개하지 않음으로써 빌 게이츠의 연봉에 대한 노출을 보호할 수 있다
3) Randomization
Randomizaton은 데이터에 random한 값을 추가하는 방식이다
이러면 개인의 특정 데이터에 대한 정확한 값을 나올 수 없다
하지만 Randomization도 "희귀 의학 분야 연구"등가 같은 상황에서 데이터에 대한 혼란을 야기할 수 있으므로 문제가 될 수 있다
CAPTCHA
Turing Test는 1950년에 {AI & 사람}을 분별하기 위해서 제작된 테스트이다

실험자 (C)는 반대편에 존재하는 인물에게 어떠한 질문을 하게 된다
그에 따라서 반대편에 존재하는 인물은 질문에 대한 응답을 할 것이다
여기서 (c)가 반대편에 있는 인물이 {인간인지 AI인지}구분을 못하게 된다면 AI입장에서는 튜링 테스트를 통과한 것이다
하지만 Turing Test를 통과한 AI는 현재까지 존재하지 않는다
CAPTCHA (Completely Automated Public Turing Test to tell Computers and Humans Apart)란 {컴퓨터 & 인간}을 구분하는 완전 자동 튜링 테스트이다
▶ Automated
Test는 컴퓨터 프로그램에 의해서 자동 생성되고 채점된다
▶ Public
프로그램과 데이터는 공개적이다
▶ Turing Test
사람은 테스트를 통과할 수 있고, 기계는 테스트를 통과할 수 없다
CAPTCHA에는 paradox가 존재한다 : 컴퓨터가 스스로 테스트를 생성하고 채점하는데 왜 기계가 통과를 못하지??
CAPTCHA는 인간의 자원에 대한 접근을 엄격하게 관리함으로써, Access Control에 꽤 쓸만하다
방화벽 (Firewall)

어떤 회사에 비서가 있고 그 비서는 회장의 스케줄을 전담한다
이 때 외부에서 손님이 찾아오려고 하면 먼저 비서에게 "그 시간에 회장이 스케줄이 되는지" 먼저 물어볼 것이다
비서는 회장의 스케줄을 통해서 그 시간에 미팅이 되는지 판단할 것이다
방화벽도 Network상에서 "비서" 역할을 수행한다
방화벽은 Network에 대한 모든 Access를 검사하고, 해당 Access가 적절한 검증을 통과한다면 들어오라고 할 것이다
- 외부 네트워크 - (방화뱍) - 내부 네트워크
방화벽에는 총 3가지의 형태가 존재한다
1. Packet Filter : Network Layer상에 위치하는 방화벽
2. Stateful Packet Filter : Transport Layer상에 위치하는 방화벽
3. Application Proxy : Application Layer상에 위치하는 방화벽 (Proxy역할을 수행한다)
1) Packet Filter (Network Layer)

패킷필터 방화벽은 Network Layer로 오는 Packet들을 검사한다
따라서 Network Layer에서 사용할 수 있는 정보만을 토대로 패킷을 걸러낸다


Packet은 캡슐화를 통해서 만들어지고 그에 따라서 Network Layer로 들어오는 것은 "TCP + IP"의 정보를 합친 패킷일 것이다
따라서 Network Layer상에 위치한 방화벽은 {Source Port / Dest Port / Source IP / Dest IP / Flags / ....}를 활용해서 패킷을 검증할 수 있다
그리고 패킷의 출입에 따라 필터링할 수 있고, 따라서 {들어오는 패킷 & 나가는 패킷}에 대해서 다른 필터링 규칙을 가질 수 있다
패킷 필터는 ACLs를 사용해서 구성된다

※ 장점
"Speed"
패킷 필터 방화벽은 패킷에 대한 처리가 Network Layer까지만 필요하고, 헤더 정보만 검사하기 때문에 전체적인 연산이 굉장히 빠르게 이루어진다
※ 단점
"No State & TCP Connection 확인 못함 & Application Data는 Blind"
패킷 필터 방화벽은 Stateless이므로 각 패킷이 모두 독립적으로 처리 된다
그리고 TCP Connection이 제대로 이루어졌는지 확인조차 불가능하다
TCP Connection 관련 문제점
Trudy는 3-way handshake 방식에서 처음 2회를 하지 않고, 마지막 차례에서 ACK bit Set을 포함한 패킷을 전송할 수 있다
하지만 정상적이라면 3-way handshake에서 SYN Flag는 반드시 존재해야 한다

근데 패킷 필터 방화벽은 state라는 개념자체가 없기 때문에 어떠한 패킷이 들어오기만 하면 "이 패킷은 tcp connection 잘 이루어졌구나"라고 판단하고 그냥 허용해버린다
이렇게 위조된 패킷이 host로 들어가게 되면 host에서는 해당 패킷에 문제가 있음을 인지할 수 있기 때문에, 바로 RST packet을 response로 보낼 것이다
하지만 위조된 패킷이 어쨌든 host에 도착했기 때문에 Trudy는 공격에 성공했다고 할 수 있다

2) Stateful Packet Filter (Transport Layer)
상태성 패킷 필터는 이전에 패킷 필터의 문제점 중 하나인 "state 개념 X"를 해결하기 위해서 탄생하였다
이를 사용한 방화벽은 Connection에 대한 정보를 유지하고 있기 때문에 Transport Layer에서 동작한다
따라서 TCP Connection(ACK)와 관련된 공격을 막을 수 있다
하지만 상태를 유지하기 때문에 일반적 패킷 필터 방화벽보다는 속도가 느리다
※ 장점
- 패킷 필터의 모든 기능 + state 유지 가능
- Ongoing Connection을 계속해서 tracking할 수 있다
※ 단점
- Application Data를 볼 수 없다
- 패킷 필터링보다 느리다
3) Application Proxy (Application Layer)
프록시 방화벽은 Application Layer을 통과하는 모든 패킷을 검증한다
따라서 주요 장점은 "Connection + Application Data 전부를 볼 수 있다"라는 것이다
하지만 단점은 "Speed"이다
Application Proxy의 특이한 점은 "데이터가 방화벽을 통과할 때 진입 패킷을 해체하고 새로운 패킷을 생성"한다는 점이다
Example)
Trudy가 이전에 패킷 필터링에서 공격했던 방식과 유사하게 여기서도 공격을 한다고 하자
Trudy는 "방화벽 너머에 있는 개방된 포트를 탐색하기 위한 Firewalk"라는 도구를 이용했다고 하자
Trudy는 {방화벽의 IP 주소 / 방화벽 내에 있는 시스템의 IP 주소 / TTL / ..}을 전부 알고 있다고 하고, Trudy가 보낼 패킷의 TTL 필드에는 "방화벽까지의 단계 개수보다 1이 더 큰 값"을 설정해서 보낸다고 하자

사실 이러한 공격은 Application Proxy에서는 통하지 않는다
왜냐하면 Proxy는 어떤 패킷이 통과할 때마다 해당 패킷을 해체하고 새로운 패킷을 생성하기 때문에 "old TTL"이 파괴된다
침임 탐지 시스템 (Intrusion Detection System)
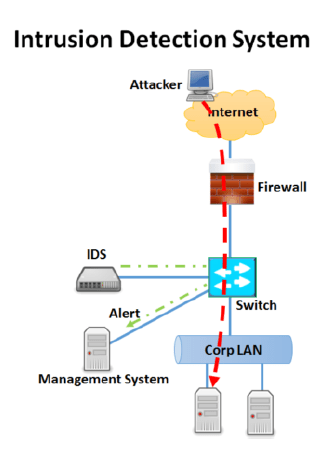
컴퓨터 보안의 핵심은 "침입자를 분리시키는 침입방지"에 있다
방화벽은 침입방지의 하나의 예시이고, 대부분의 바이러스 방어도 이에 해당된다
하지만 아무리 침입방지를 뛰어나게 구현해도, 뚫리는 경우는 존재할 것이다
이렇게 누군가 시스템이 침입했을 때 이를 감지할 수 있는 "침입탐지 시스템"이 필요하다
IDS는 "로그 파일 분석"에서부터 발전해온 기술이다
보통 침입자가 시스템에 공격을 가한다면 시스템상에 "로그"가 남을 것이다.
이러한 로그들을 분석해서 언제 누가 공격했는지 파악이 가능하다
하지만 로그가 남는다는 것은 다르게 보면 이미 침입자가 공격을 완료했다는 의미이기 때문에, 남은 로그를 분석해서 찾는것은 그만큼 대응이 느려지는 문제가 있다
- 침입자가 생각이 조금이라도 있다면 공격을 마치고 로그 파일을 지우고 도망갈 것이다
>> 따라서 로그 분석말고 침입자가 침입을 한 시점에서부터 감지해서 prevention을 해주자
IDS는 침입을 "감지"만 해주는 것이지 "감지 후 해결"해주는 것은 아니다
(1) 어떤 방식으로 탐지
▶ Signature-Based IDS
알려진 흔적(로그)나 패턴을 기반으로 공격을 탐지하는 방식이다
가장 대표적인 예는 "로그인 실패 횟수 탐지"이다
일정 횟수 이상으로 로그인을 실패하면 시스템상에서 아예 로그인을 막아버린다
이러한 방식의 장점은 {단순성, 효율성, "알려진 공격에 대한 탐지가 뛰어나다"}이다
Signature의 의미가 "공격 방식만이 가지는 고유한 특성"을 의미한다
따라서 이러한 Signature를 모아두어서 나중에 공격이 들어오면 패턴을 분석해서 감지하는 방식이다
그런데 이를 뒤집어서 보면 "알려지지 않은 공격"에 대해서는 그냥 뚫린다는 의미이다
<장점>
- 구조상으로 간단하다
- 알려진 공격에 대해서는 쉽게 탐지 가능
- 한번 탐지되면 공격에 대한 구체적인 정보를 알아낼 수 있다 {어떤 공격인지 / 누가 공격한건지 / 어떤식으로 공격했는지 / ...}
- 합리적인 Signature 개수라면 꽤 효율적이다
<단점>
- Signature File을 보존해야 한다
- Signature 개수가 점점 많아진다
- 알려진 공격에 대해서만 탐지 가능
- 알려진 공격의 변형 or 알려지지 않은 공격은 탐지가 불가능하다
▶ Anomaly-Based IDS
시스템의 기준을 정해서 기준을 벗어난 이상한 점이 포착될 때마다 IDS는 경고를 제공한다
일단 이러한 방식을 적용하려면 먼저 "시스템이 정상적이라는 것이 무엇인지"부터 정의해야 한다
정의하기 위해서는 통계학적으로 "평균 / 분산"의 개념이 필요하다
예를 들어서 시스템에는 {open / read / close} 3가지 명령어만 사용된다고 하자
그러면 정상적인 시스템이라면 명령어들을 다음과 같은 집합으로 나눌 수 있다
open read close open open read close .......
>> (open, read) (read, close) (close, open) (open, open)
이를 통해서 (read, open) (close, read)같은 명령어는 비정상이라고 판단할 수 있다
또 다른 예로는 Alice가 특정 파일에 대한 비율을 따로 저장해놨다고 하자

1시간 뒤쯤, 다시 Alice가 파일에 대해 access하고 그 비율을 저장해놓은 것이 있다고 하자

이 때 이러한 접근이 정상인지 비정상인지 판단해보자
(H-A)^(2) >> 0 + 0 + (0.1)^2 + (0.1)^2 = 0.02
그리고 0.1 이하는 정상이라고 판단한다고 기준을 세웠다고 하면, 위의 접근은 정상 접근이라고 판단할 수 있다
근데 파일 접근에 대한 비율은 항상 변경될 수 있기 때문에 "기준 비율"을 점점 변화해가야 한다

이러한 계산을 통해서 "기준 비율"을 다음과 같이 변경하였다

<장점>
- 알려지지 않은 여러가지 공격에 대해서 탐지 가능
- Signature를 관리할 필요가 없다
<단점
- 어쨌든 정확한 기준은 없기 때문에 탐지에 대한 정확성이 떨어질 수 있다
- 그에 따라서 신뢰성에도 문제가 존재한다
(2) 뭘 보호하는지
▶ Host-Based IDS
Host(End System)내부에서 여러가지 활동 내역들을 모니터링하고 침입을 감지하는 방식이다
- 백신 프로그램 : 침입자가 멀웨어같은거를 설치하고 도망가려고 하면 이런 공격행위를 감지하고 host에게 알려준다
▶ Network-Based IDS
네트워크 자체를 보호하기 위한 것이다
- 네트워크 패킷 자체를 모니터링해서 네트워크를 통해서 어떤 공격이 시도되고 있는지를 감지한다
- 갑자기 패킷이 폭주된다면 DDOS를 의심해서 경고를 제공한다
IDS는 탐지만하고 예바아은 하지 않는다. 이를 해결하기 위해서 IPS(Intrusion Prevention System)이라는 것이 나왔다
IPS란, 침입을 탐지했으면 거기에 대한 대응까지 해주는 것이다
탐지를 했으면 alarm을 보내고, firewall에 접근해서 새로운 rule을 추가함으로써 대응을 한다
