2022. 1. 25. 18:02ㆍMajor`/컴퓨터구조
명령어 파이프라이닝 (Instruction Pipelining)
- CPU의 성능 ≒ 컴퓨터시스템의 프로그램 처리 시간에 직접적 영향
- 속도를 향상시키면 향상시킬수록 매우 좋다
- 속도를 향상시키는 방법 중 하나 : 명령어 파이프라이닝 ≫ 매우 간단하면서 분명한 효과
1. 명령어를 실행하는데 사용되는 하드웨어를 여러 개의 독립적인 단계(stage)들로 분할
2. 각 단계별로 동시에 서로 다른 명령어들을 처리 → CPU 성능 향상
3. 분할되는 단계가 많이질수록 CPU의 성능은 향상
가장 효율적인 파이프라인 조건
- 각 단계별 처리 시간 일정
- 각 명령의 처리 단계 균일
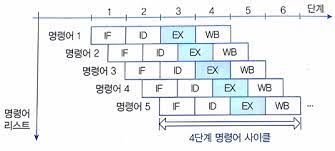
2-단계 명령어 파이프라이닝
- 명령어 사이클은 기본적으로 인출 사이클/실행 사이클 : 2개의 단계로 구성
- 이 2개의 단계들을 처리하는 하드웨어를 독립적인 모듈로 구성
- 각 모듈이 서로 다른 명령어를 동시에 처리 가능
≫ 명령어를 실행하는 하드웨어를 인출 단계/실행 단계 : 2개의 파이프라인 단계들로 분리해서 구성
- 두 파이프라인 단계들에 하나의 클록 신호를 동시에 인가하면
- 해당 단계들의 동작 시간을 일치시킬 수 있다
- 그러면, 각 단계는 서로 다른 명령어에 대해서 각자 다른 동작을 수행

속도 향상의 원리 (From Example)
- 명령어1은 두 클록주기만에 종료
- 명령어2부터는 한 클록 후에 실행이 완료
- 각 명령어마다 걸리는 시간은 두 클록주기이지만, 파이프라이닝 특성에 의해서 두번째 명령어부터는 한 클록주기만에 실행이 완료되는 것과 같은 효과
if 파이프라이닝 이용 X
- 각 명령어들은 두 클록주기가 필요
- 2 × 3 = 총 6클록주기 소요
if 파이프라이닝 이용 O
두 번째 명령어부터 한 클록주기만 필요
- 총 4클록주기 소요
>> 속도향상(Sp) = 1.5배
- 최종적으로 명령어의 수가 굉장히 많아지면
- 얻을 수 있는 최대 속도 향상 ≒ 2배
- but, 이런 속도향상은 인출/실행이 같은 길이의 시간이 소요되는 경우에만 얻을 수 있다
▶ 문제점
- 두 단계의 처리 시간이 동일하지 않으면 2배의 속도향상을 얻지 못한다 (파이프라인 효율 저하)
- 일반적으로, 실행 시간 > 인출 시간
▶ 해결책
- 파이프라인 단계의 수를 증가시켜서 각 단계의 처리 시간을 같게 만든다
- 파이프라인 단계의 수를 늘리면 전체적으로 속도 향상이 더 높아진다
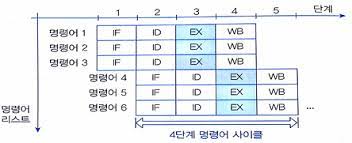
4-단계 명령어 파이프라이닝
각 파이프라인 단계
1. 명령어 인출 (IF)
- 명령어를 기억장치로부터 인출
2. 명령어 해독 (ID)
- 해독기(decoder)를 이용해서 명령어 해석
3. 오퍼랜드 인출 (OF)
- 기억장치로부터 오퍼랜드 인출
4. 실행 (EX)
- 지정된 연산을 수행하고, 결과를 저장

속도 향상 (From Example)
Condition : 파이프라인 단계 수 : k / 실행할 명령어의 수 : N
if 파이프라이닝 이용 X
- 전체 실행 시간 T = k × N
if 파이프라이닝 이용 O
- 명령어 1의 경우 k의 클록주기만큼 시간 소요
- 명령어 2부터는 한 주기씩만 소요
- → 전체 실행 T = k + (N - 1)
∴ 최종 속도 향상
>> Sp = (k × N) / k + (N - 1)
- k-단계 파이프라인 : 최대 k배의 속도 향상
슈퍼 파이프라인 (Super Pipeline)
- 하나의 파이프라인을 여러 부분으로 나눠서 연속적인 흐름과정을 처리
- 이전의 명령어 사이클이 끝나기 전에 다음 명령어의 사이클이 시작
- 클럭이 높아짐에 따라서 나누기가 힘들어져서 잘 사용하지 않는다
- 명령어 1의 경우 k의 클록주기만큼 시간 소요
- 다음 명령어부터 명령어 2개가 한 주기씩 소요
슈퍼 스칼라 (Super Scala)
- CPU의 처리 속도를 더 높이기 위해서, 내부에 2개 이상의 명령어 파이프라인들을 포함
- 매 사이클마다 각 명령어 파이프라인이 별도의 명령어를 인출해서 동시에 실행
- k-way Super Scala는 매 주기마다 명령어를 k개씩 인출해서 동시에 처리
- 각 명령어들 사이에 데이터 의존성이 존재하지 않아야 동시에 실행 가능
- 데이터 의존성 : 이전 명령어의 결과가 다음 명령어에 영향을 주는 관계
속도 향상 (From Example)
Condition : 파이프라인 단계 수 : k / 실행할 명령어의 수 : N
if k단계 명령어 파이프라인 1개 사용
- T(1) = k + (N - 1)
if k단계 명령어 파이프라인 m개 사용
- 처음 m개의 명령어 = k주기 소요
- 그 다음부터 매 주기마다 m개의 명령어들이 동시에 실행 완료
- T(m) = k + (N - m) / m
∴ 최종 속도 향상
>> Sp = T(1)/T(m) = {k + (N - 1)} / {k + (N - m) / m}
- N이 무한대로 많아지면 속도 향상은 m에 근접
→ 슈퍼 스칼라 프로세서의 속도는 일반 파이프라인에 비해 최대 mk배까지 속도향상
슈퍼 파이프라인 슈퍼 스칼라 (Super Pipeline Super Scala)
- m개의 명령어 파이프라인들을 이전에 실행된 n개의 명령어 파이프라인의 실행이 종료되기전에 실행

파이프라인 효율 저하 요인
① 모든 명령어들이 파이프라인 단계들을 모두 거치지는 않는다
- 어떤 명령어는 오퍼랜드를 인출할 필요가 없을 수 있기 때문에, OF 단계를 수행하지 않아도 된다
- 파이프라인 하드웨어를 단순화시키기 위해서는 모든 명령어가 각 단계를 모두 통과해야 한다
- 결과적으로, OF 단계를 수행하는데 걸리는 시간이 필요 없이 소모
② 파이프라인 클록은 처리 시간이 가장 오래 걸리는 단계를 기준으로 결정
- 만약 IF, ID, OF단계 처리 : 1ns / EX단계 처리 : 1.5ns
- 최종 클록 주기 = 1.5ns
▶ 보완 방법
- 파이프라인 단계들을 더 작게 분할
- 처리 시간의 차이를 최소화시켜주는 슈퍼파이프라이닝 기술 사용
③ IF단계, OF단계는 기억장치를 액세스해야 하는데, 하나의 기억장치 모듈을 두 단계가 동시에 액세스할 수 없기 때문에 지연이 발생
▶ 보완 방법
- IF단계, OF 단계가 직접 액세스하는 CPU 내부 캐시를 명령어 캐시/데이터 캐시로 분리
④ 조건 분기 명령어가 실행되면, 미리 인출되어서 파이프라인에 처리되고 있던 명령어들이 무효화
※ Example) 명령어 3 : JZ 12; Jump (if zero) to address 12
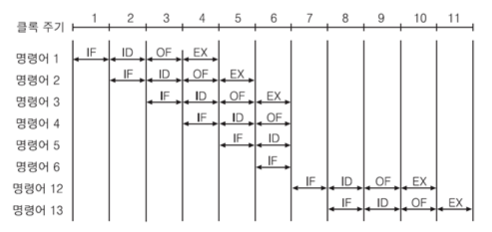
▶ 보완 방법
(1) 분기 예측
1. 분기가 일어날 것인지를 예측
- 그에 따라 어느 경로의 명령어를 인출할 지를 결정하는 확률적 방법
2. 최근 분기결과들을 저장해놓은 분기 역사 표를 참조해서 예측
(2) 분기 목적지 선인출
- 조건 분기가 인식되면
- 분기 명령어의 다음 명령어 + (조건이 만족될 경우) 분기하게 될 목적지의 명령어를 함께 인출
- 조건 확인 후, 유효 명령어 결과를 선택
- 분기 목적지 명령어를 별도로 저장해놓을 기억 장소가 추가되어야 한다
(3) 루프 버퍼
- 루프 버퍼 : 파이프라인의 명령어 인출 단계에 포함되어 있는 작은 고속 기억장치
- 가장 최근에 인출된 n개의 명령어들을 순서대로 저장
- 작은 반복 루프들이 포함된 프로그램을 처리할 경우 효과가 높다
(4) 지연 분기
- 프로그램 내의 명령어들을 재배치함으로써 파이프라인의 성능 개선
- 분기 명령어의 위치를 재배치해서, 원래보다 나중에 실행하게 해서 성능 저하 최소화
상태 레지스터 (Status Register)
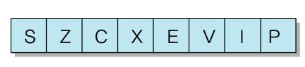
- 조건 분기 명령어에서 사용되는 조건들(조건 플래그)을 저장
- 조건 플래그 : 조건의 상태를 나타내는 비트들
▶ 부호 플래그 (S)
- 직전에 수행된 산술 연산 결과값의 부호 비트
- 양수 : 0
- 음수 : 1
▶ 제로 플래그 (Z)
- 연산 결과값
- 결과 != 0 : 0
- 결과 == 0 : 1
▶ 올림수 플래그 (C)
- 덧셈/뺄셈에서 carry 발생 여부
- carry 발생 X : 0
- carry 발생 O : 1
▶ 동등 플래그 (E)
- 두 수 일치여부
- 두 수 불일치 : 0
- 두 수 일치 : 1
▶ 오버플로우 플래그 (V)
- 산술 연산 과정에서 오버플로우 발생여부
- 오버플로우 발생 X : 0
- 오버플로우 발생 O : 1
▶ 인터럽트 플래그 (I)
- 인터럽트 가능 여부
- "인터럽트 가능" : 0
- "인터럽트 불가능" : 1
▶ 슈퍼바이저 플래그 (P)
- CPU 모드 user? Supervisor?
- CPU 실행모드가 사용자 모드 : 0
- CPU 실행모드가 슈퍼바이저 모드 : 1
파이프라인 해저드 (Hazard)
- 파이프라인 프로세서에서 명령어 의존성(데이터, 컨트롤, 자원)을 발생 시킬 수 있는 문제
- 파이프라인의 성능을 저해하는 요인, CPI(명령어당 실행 클럭 수)가 1이 되는 것을 방해하는 요소
- CPI : CPU가 1개의 명령어를 처리하는데 소요되는 평균 사이클 수
해저드 종류
구조적 해저드 (Structural Hazards)
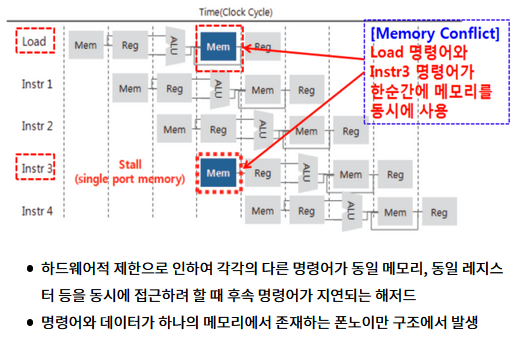
- 파이프라인의 두 명령어가 동시에 한 하드웨어에 접근할 때 발생 (같은 메모리에 접근)
- 하드웨어가 병행 수행을 지원하지 않는 경우, 자원 충돌(Resource Conflicts) 발생
▶ 해결방안
(1) 하드웨어/리소스 추가
- (리소스, 하드웨어)를 추가해서 메모리 동시 접근
- → 하드웨어 병렬 구성
(2) 하버드 아키텍쳐 사용
- 데이터, 명령어를 각각의 메모리에 분리해서 메모리 동시 접근
- → 데이터 메모리/명령어 메모리 분리
(3) 메모리 인터리빙
- 메모리 모듈별로 병렬 접근을 수행해서 메모리 동시 접근
- → 인터리빙을 통한 하드웨어 병렬 구성
(4) 지연
- nop 명령어를 추가해서, 파이프라인 수행을 일시정지
- → nop 명령어 수행
데이터 해저드 (Data Hazards)
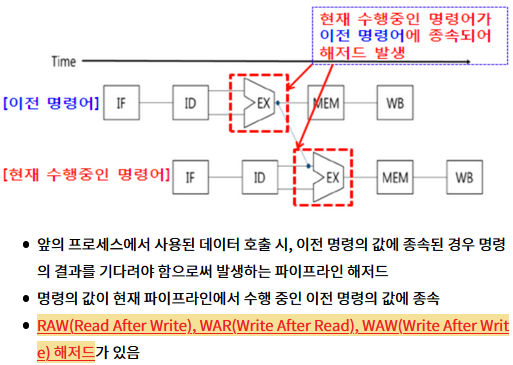
- 현재 파이프라인에서 수행중인 명령에 사용되는 데이터가 다음 파이프라인에서도 사용될 경우
- 다음 파이프라인은 현재 파이프라인이 해당 데이터를 다 쓸때까지 기다려야 한다
- 명령 값이 이전 명령에 종속되어 대기
▶ 해결방안
(1) 전방전달
- 레지스터 파일에 반영되기 전에 EX단계에서 계산된 결과를 다음 수행단계로 전달
- 하드웨어 추가 필요
(2) 지연
- 컴파일러 수준에서 해저드를 발견하고 nop 명령어 삽입
(3) 비순차 실행
- 접근 중인 데이터와 관련 없는 명령어를 삽입해서 실행
- 컴파일러 수준에서 코드 실행 변경
(4) 프로그래밍 방식
- 변수를 늘리거나, 계산이 완료된 후 한번에 실행해서 데이터 해저드를 최소화
- 레지스터를 고려해서 프로그래밍
제어 해저드 (Control Hazards)
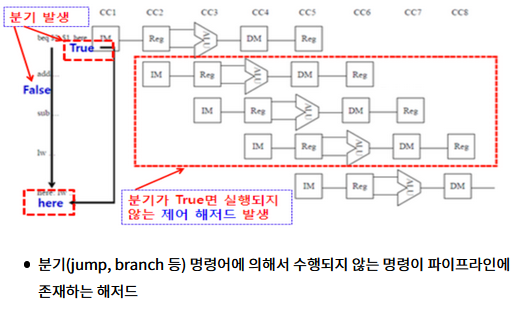
- jump, branch등의 명령어에 의해 발생하는 래저드
- 분기 명령어에 의해서 수행되지 않는 명령이 파이프라인에 존재
▶ 해결방안
(1) 분기예측
- 명령이 분기하는지 미리 예측해서, 명령어를 변화
- 정적예측, 동적예측
(2) 브랜치 지연
- 컴파일러가 분기문을 발견하면, nop / 분기와 관련 없는 명령을 추가해서 프로그램 순서 재배치
- 비순차 실행과 유사
(3) 프로그래밍 방식
- 조건분기를 최소화하도록 프로그래밍해서 제어 해저드를 최소화
- inline 메소드 사용 / Loop unrolling 사용
| 구분 | Example | 설명 |
| 파이프라인 |  |
T = k + (N - 1) |
| 슈퍼 파이프라인 |  |
T = (k + 1) / {n×(N - 1)} |
| 슈퍼 스칼라 |  |
T = k + (N - m) / m | 단순 파이프라인과 성능 비교 Sp = {k + (N - 1)} / {k + (N - m) / m} |
| 슈퍼 파이프라인 슈퍼 스칼라 |
 |
T = k + (N - m) / (m × n) |
| T : 명령어 실행 시간 k : 파이프라인 단계 N : 실행 명령어 개수 |
||