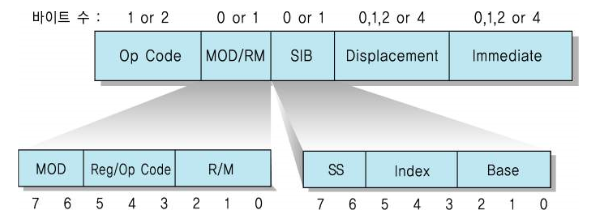
2022. 1. 29. 15:18ㆍMajor`/컴퓨터구조
목차
- 명령어 세트 (Instruction Set)
- 연산 종류 (Operation Repertoire)
- CALL/RET 마이크로 연산
- 데이터 형태 (Data Type)
- 명령어 형식 (Instruction Format)
- 주소지정 방식
- 표기 방식
- (1) 직접 주소지정 방식 (Direct Addressing Mode)
- (2) 간접 주소지정 방식 (Indirect Addressing Mode)
- (3) 묵시적 주소지정 방식 (Implied Addressing Mode)
- (4) 즉시 주소지정 방식 (Immediate Addressing Mode)
- (5) 레지스터 주소지정 방식 (Register Addressing Mode)
- (6) 레지스터 간접 주소지정 방식 (Register-Indirect Addressing Mode)
- (7) 변위 주소지정 방식 (Displacement Addressing Mode)
- 실제 상용 프로세서들의 명령어 형식
명령어 세트 (Instruction Set)
- CPU마다 명령어의 종류, 개수가 서로 다르다
- 하나의 CPU에 대한 명령어들의 집합 : 명령어 세트
명령어 세트 설계 고려 사항
1. 연산 종류
2. 데이터 형태
3. 명령어 형식
4. 주소지정 방식
연산 종류 (Operation Repertoire)
- CPU가 수행할 연산들의 수, 종류, 복잡도
반드시 수행하는 기본적 연산
▶ Data 전송
- (Register ↔ Register) / (Register ↔ Memory) / (Memory ↔ Memory) 간에 Data를 이동하는 동작
- 이 과정에서 Memory의 주소를 계산하는 경우도 있다
▶ 산술 연산
- 덧셈/뺄셈/곱셈/나눗셈과 같은 기본적인 산술 연산
▶ 논리 연산
- Data의 각 bit들에 대한 AND/OR/NOT/exclusive-OR과 같은 논리 연산 수행
▶ 입출력 (I/O)
- (CPU ↔ (Memory, I/O장치) 간의 Data 이동을 위한 동작 수행
- 특수한 I/O 명령어, 주소지정 방식이 필요하다
▶ 프로그램 제어
- 명령어의 실행 순서를 변경하는 연산들이 필요
- 분기(branch), 서브루틴 호출(subroutine call)등이 존재
※ 서브 루틴 호출
CALL 명령어
- 서브루틴 호출 명령어
RET 명령어
- 서브루틴 → 원래 프로그램으로 복귀시키는 명령어
CALL/RET 마이크로 연산
CALL X 명령어
- 복귀할 주소가 stack에 저장되어야 한다
t(0) : PC -> MBR t(1) : SP -> MAR / X -> PC t(2) : MBR -> M[MAR] / SP - 1 -> SP
(1) t(0) : PC -> MBR
- 현재 PC 내용(복귀할 주소)를 CPU 내부 버스를 통해서 MBR로 전달
(2) t(1) : SP -> MAR / X -> PC
- 현재 SP(스택의 최상단의 주소)를 CPU 내부 버스를 통해서 MAR로 전달
- 서브루틴 X의 주소를 PC에 저장
(3) t(2) : MBR -> M[MAR] / SP - 1 - > SP
- 복귀할 주소를 SP(스택의 최상단)에 저장
- SP - 1을 통해서 항상 SP는 스택의 최상단을 가리키게 해준다
- 만약, 주소지정 단위가 byte이고 저장될 주소가 16bit면 SP의 값은 2를 감소시켜야 한다
RET 명령어
- stack에 저장되어있는 복귀 주소를 인출해서 PC에 적재함으로써 원래 프로그램으로 복귀
t(0) : SP + 1 -> SP t(1) : SP -> MAR t(2) : M[MAR] -> PC
(1) t(0) : SP + 1 -> SP
- SP + 1을 통해서 SP가 마지막으로 저장된 복귀주소를 가리키게 만든다
(2) t(1) : SP -> MAR
- 마지막으로 저장된 복귀주소의 주소를 CPU 내부 버스를 통해서 MAR로 전달
(3) t(2) : M[MAR] -> PC
- stack에서 해당 주소의 Data(복귀주소)를 인출해서 PC에 저장
※ Example

프로그램 실행
- 200 ~ 210
CALL SUB1 : SUB1 호출 명령
- 250 ~ 260
CALL SUB2 : SUB2 호출 명령
- 300 ~ RET
RET : 원래 프로그램으로 복귀 (260)
- 261 ~ 280
CALL SUB2 : SUB2 호출 명령
- 300 ~ RET
RET : 원래 프로그램으로 복귀 (280)
- 281 ~
RET : 원래 프로그램으로 복귀 (210)
- 211 ~ END
프로그램 종료
(1) 프로그램 실행
| MEMORY | 200 | 주 프로그램 |
||
| ... | ||||
| 210 (CALL SUB1) |
||||
| 211 | ||||
| .... | ||||
| (END) | ||||
| 250 | 서브루틴 SUB1 |
|||
| .... | ||||
| 260 (CALL SUB2) |
||||
| 261 | ||||
| .... | ||||
| 280 (CALL SUB2) |
||||
| 281 | ||||
| ..... | ||||
| RET | ||||
| 300 | 서브루틴 SUB2 |
|||
| ..... | ||||
| SP | RET | |||
| 프로그램 실행 | ||||
- 200 ~ 210까지 순서대로 실행
- 210에서 CALL SUB1 명령어 실행
(2) CALL SUB1
| MEMORY | 200 | 주 프로그램 |
||
| ... | ||||
| 210 (CALL SUB1) |
||||
| 211 | ||||
| .... | ||||
| (END) | ||||
| 250 | 서브루틴 SUB1 |
|||
| .... | ||||
| 260 (CALL SUB2) |
||||
| 261 | ||||
| .... | ||||
| 280 (CALL SUB2) |
||||
| 281 | ||||
| ..... | ||||
| RET | ||||
| 300 | 서브루틴 SUB2 |
|||
| SP | ..... | |||
| 211 | RET | |||
| CALL SUB1 | ||||
1. 서브루틴 종료 후, 복귀할 주소인 211을 스택에 저장 후, SP - 1을 통해서 SP가 항상 스택의 최상단을 가리키게 한다
2. SUB1 실행
- 250 ~ 260까지 순서대로 실행
- 260에서 CALL SUB2 명령어 실행
(3) CALL SUB2
| MEMORY | 200 | 주 프로그램 |
||
| ... | ||||
| 210 (CALL SUB1) |
||||
| 211 | ||||
| .... | ||||
| (END) | ||||
| 250 | 서브루틴 SUB1 |
|||
| .... | ||||
| 260 (CALL SUB2) |
||||
| 261 | ||||
| .... | ||||
| 280 (CALL SUB2) |
||||
| 281 | ||||
| ..... | ||||
| RET | ||||
| SP | 300 | 서브루틴 SUB2 |
||
| 261 | ..... | |||
| 211 | RET | |||
| CALL SUB2 | ||||
1. 서브루틴 종료 후, 복귀할 주소인 261을 스택에 저장 후, SP - 1을 통해서 SP가 항상 스택의 최상단을 가리키게 한다
2. SUB2 실행
- 300 ~ RET까지 순서대로 실행
- RET명령어를 만났기 때문에 SP - 1을 통해서 마지막 복귀주소를 인출 : 261
- 261을 PC에 저장함에 따라 해당 복귀 주소(261)에서 프로그램 실행
(4) RET
| MEMORY | 200 | 주 프로그램 |
||
| ... | ||||
| 210 (CALL SUB1) |
||||
| 211 | ||||
| .... | ||||
| (END) | ||||
| 250 | 서브루틴 SUB1 |
|||
| .... | ||||
| 260 (CALL SUB2) |
||||
| 261 | ||||
| .... | ||||
| 280 (CALL SUB2) |
||||
| 281 | ||||
| ..... | ||||
| RET | ||||
| 300 | 서브루틴 SUB2 |
|||
| SP | ..... | |||
| 211 | RET | |||
| RET | ||||
- 261로 복귀해서 261 ~ 280까지 순서대로 실행
- 280에서 CALL SUB2 명령어 실행
(5) CALL SUB2
| MEMORY | 200 | 주 프로그램 |
||
| ... | ||||
| 210 (CALL SUB1) |
||||
| 211 | ||||
| .... | ||||
| (END) | ||||
| 250 | 서브루틴 SUB1 |
|||
| .... | ||||
| 260 (CALL SUB2) |
||||
| 261 | ||||
| .... | ||||
| 280 (CALL SUB2) |
||||
| 281 | ||||
| ..... | ||||
| RET | ||||
| SP | 300 | 서브루틴 SUB2 |
||
| 281 | ..... | |||
| 211 | RET | |||
| CALL SUB2 | ||||
- 300 ~ RET까지 순서대로 실행
- RET 명령어가 실행됨에 따라 스택의 최상단에 존재하는 복귀주소 (281)을 인출해서 PC에 저장
(6) RET
| MEMORY | 200 | 주 프로그램 |
||
| ... | ||||
| 210 (CALL SUB1) |
||||
| 211 | ||||
| .... | ||||
| (END) | ||||
| 250 | 서브루틴 SUB1 |
|||
| .... | ||||
| 260 (CALL SUB2) |
||||
| 261 | ||||
| .... | ||||
| 280 (CALL SUB2) |
||||
| 281 | ||||
| ..... | ||||
| RET | ||||
| 300 | 서브루틴 SUB2 |
|||
| SP | ..... | |||
| 211 | RET | |||
| RET | ||||
1. 281로 복귀해서 281 ~ RET까지 순서대로 실행
2. RET명령어를 만남으로써 스택에 존재하는 복귀주소(211)을 인출해서 PC에 저장
(7) RET
| MEMORY | 200 | 주 프로그램 |
||
| ... | ||||
| 210 (CALL SUB1) |
||||
| 211 | ||||
| .... | ||||
| (END) | ||||
| 250 | 서브루틴 SUB1 |
|||
| .... | ||||
| 260 (CALL SUB2) |
||||
| 261 | ||||
| .... | ||||
| 280 (CALL SUB2) |
||||
| 281 | ||||
| ..... | ||||
| RET | ||||
| 300 | 서브루틴 SUB2 |
|||
| ..... | ||||
| SP | RET | |||
| RET | ||||
1. 211로 복귀해서 211 ~ END까지 순서대로 진행
2. END를 만남으로써 프로그램 종료
데이터 형태 (Data Type)
- 연산이 수행될 Data들의 형태 : Data 길이(비트 수), 수의 표현 방식(정수, 부동소수점 수)
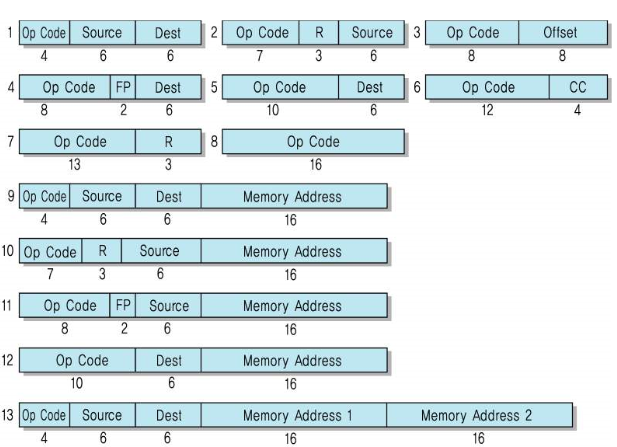
명령어 형식 (Instruction Format)
- 명령어의 길이 / Operand Field들의 개수/길이
- 명령어는 CPU에 의해 실행될 때 필요한 모든 정보를 포함하고 있어야 한다
- 명령어의 bit들은 용도에 따라 몇개의 필드(field)로 나눌 수 있다
정보
연산 코드 (Operation Code)
- 수행할 연산을 지정
- LOAD, ADD,....
오퍼랜드 (Operand)
- 연산을 수행할 때 필요한 Data or Data의 주소
- 각 연산은 입력 오퍼랜드(1~2개) / 결과 오퍼랜드(1개)를 가질 수 있다
- Data는 CPU 레지스터 or 기억장치에 위치한다
다음 명령어 주소 (Next Instruction Address)
- 현재 명령어 실행이 완료되고, 다음 명령어를 인출할 위치
- 순차적으로 실행될 경우 필요 없다
- 분기/호출 명령어와 같이 순서가 변경될 때만 필요하다
0-주소 명령어
- 연산코드만 존재하고, 오퍼랜드가 존재하지 않는 명령어
- 모든 연산은 SP가 가리키는 오퍼랜드를 이용해서 명령 수행
- STOR명령어를 사용하지 않는다
- PUSH, POP 사용
- stack을 사용해서 수식을 계산하기 위해서는 수식을 postfix형태로 변경해야 한다
| 연산 코드 (Operation Code) |
1-주소 명령어
- 명령어가 1개의 오퍼랜드만 포함
- 오퍼랜드의 모든 비트들을 주소지정에 사용할 수 있어서 더 넓은 영역의 주소들을 지정할 수 있다
- 누산기(AC)를 이용해서 명령어를 처리
- ex) LOAD X ; M[X] -> AC (X번지 Data를 AC에 저장)
| 연산 코드 (Operation Code) |
Operand |
| Data 1의 주소 |
2-주소 명령어
- 명령어가 2개의 오퍼랜드를 포함 - (가장 일반적으로 사용)
- 여러 개의 범용 레지스터(GPR)를 가진 컴퓨터에서 사용
- ex) MOV X, Y ; M[Y] -> M[X] (Y번지 Data를 X번지로 이동 / X, Y는 주소)
| 연산 코드 (Operation Code) |
Operand 1 | Operand 2 |
| - Data 1의 주소 - 연산 결과 주소 |
Data 2의 주소 |
▶ 장점
- 3주소 명령어에 비해 명령어 길이가 짧다
- 계산 결과가 기억장치에 저장되고, CPU에도 남아있어서 시간이 절약된다
- 실행 속도가 빠르고 기억장치 효율이 좋다
▶ 단점
- 연산 결과가 주로 Operand(1)에 저장되므로 원래 Operand(1)에 있던 Data가 사라진다
- 전체 프로그램 길이가 길어진다
3-주소 명령어
- 명령어가 3개의 오퍼랜드를 포함
- 여러 개의 범용 레지스터(GPR)를 가진 컴퓨터에서 사용
- 연산 결과가 Operand(3)에 저장된다
| 연산 코드 (Operation Code) |
Operand 1 | Operand 2 | Operand 3 |
| Data 1의 주소 | Data 2의 주소 | Data 3의 주소 |
▶ 장점
- 연산 결과를 Operand 영역 중 하나를 사용해서 저장하기 때문에 연산 시 원래의 Data가 사리지지 않는다
- 프로그램 전체 길이가 짧아진다
- 명령 인출을 위해 주기억장치에 접근하는 횟수가 줄어든다
▶ 단점
- 명령어 1개의 길이가 너무 길어진다
- 하나의 명령을 수행하기 위해서 기억장치에 최소 4번 접근해야 하기 때문에 수행시간이 길어진다
※ Example : X = (A + B) × (C - D)
| 명령어 | 동작 |
| ADD | 덧셈 |
| SUB | 뺄셈 |
| MUL | 곱셈 |
| DIV | 나눗셈 |
| MOV | Data 이동 |
| LOAD | 기억장치에서 Data 읽어서 AC에 저장 |
| STOR | AC 내용을 기억장치에 저장 |
(1) 0-주소 명령어
100 PUSH A ; 스택에 A PUSH 101 PUSH B ; 스택에 B PUSH 102 ADD ; 스택 가장 위의 값(A, B)를 POP해서 더하고 연결 결과를 다시 PUSH 103 PUSH C ; 스택에 C PUSH 104 PUSH D ; 스택에 D PUSH 105 SUB ; 스택 가장 위의 값(C, D)를 POP해서 빼고 연산 결과를 다시 PUSH 106 MUL ; 스택 가장 위의 값(A+B, C-D)를 POP해서 곱하고 연산 결과를 다시 PUSH 107 POP ; 기억장치 X번지에 결과를 POP
| Stack | |||
| SP → | B | ||
| A | SP → | A+B | |
| (1) | (2) | ||
| SP → | D | ||
| C | SP → | C-D | |
| A+B | A+B | ||
| (3) | (4) | ||
| SP → | (A+B) × (C-D) | ||
| (5) | |||
(2) 1-주소 명령어
- 계산 과정에서 중간 결과를 임시 저장하는 기억장치 : T
- 1-주소 명령어를 사용하는 CPU는 내부 레지스터가 AC만 존재하기 때문에 중간 결과를 따로 저장할 기억장치가 필요하다
100 LOAD A ; M[A] -> AC >> 기억장치 A의 내용을 AC에 저장 101 ADD B ; AC + M[B] -> AC >> AC의 내용(A)과 기억장치 B의 내용을 더해서 AC에 저장 102 STOR T ; AC -> M[T] >> AC의 내용(A+B)를 임시 기억장치 T에 저장 103 LOAD C ; M[C] -> AC >> 기억장치 C의 내용을 AC에 저장 104 SUB D ; AC - M[C] -> AC >> AC의 내용(C)과 기억장치 D의 내용을 빼서 AC에 저장 105 MUL T ; AC X M[T] -> AC >> AC의 내용(C-D)과 기억장치 T의 내용(A+B)를 곱해서 AC에 저장 106 STOR X ; AC -> M[X] >> AC의 내용{(A+B) X (C-D)}를 기억장치 X에 저장
(3) 2-주소 명령어
- 여러 개의 CPU 레지스터를 사용할 수 있다
100 MOV R1, A ; M[A] -> R1 >> 기억장치 A의 Data를 레지스터 R1로 이동 101 ADD R1, B ; R1 + M[B] -> R1 >> R1의 내용(A)과 기억장치 B의 Data를 더해서 R1에 저장 102 MOV R2, C ; M[C] -> R2 >> 기억장치 C의 Data를 레지스터 R2로 이동 103 SUB R2, D ; R2 - M[D] -> R2 >> R2의 내용(C)과 기억장치 D의 Data를 빼서 R2에 저장 104 MUL R1, R2 ; R1 X R2 -> R1 >> R1의 내용(A+B)과 R2의 내용(C-D)를 곱해서 R1에 저장 105 MOV X, R1 ; R1 -> M[X] >> R1의 내용{(A+B) X (C-D)}를 기억장치 X번지에 저장
(4) 3-주소 명령어
100 ADD R1, A, B ; M[A] + M[B] -> R1 >> 기억장치 A 내용과 기억장치 B 내용을 더해서 R1에 저장 101 SUB R2, C, D ; M[C] - M[D] -> R2 >> 기억장치 C 내용과 기억장치 D 내용을 빼서 R2에 저장 102 MUL X, R1, R2 ; R1 X R2 -> M[X] >> R1 내용과 R2 내용을 곱해서 기억장치 X번지에 저장
주소지정 방식
- Operand의 주소를 지정하는 방식
- 명령어의 길이가 늘어나면 Operand 필드의 수와 각 필드의 비트 수가 증가할 수 있다
- but, 명령어 비트의 수는 단어의 길이와 같다
- 제한된 명령어 비트들을 이용해서 (1) 다양한 방법으로 오퍼랜드 지정 + (2) 더 큰 용량의 기억장치를 사용할 수 있도록 하기 위해서 여러 가지 주소지정 방식이 존재한다
표기 방식
명령어가 실행되는 과정에서 주소지정 방식에 따라 최종적인 EA가 결정
- EA : 실제 Data를 읽어오기 위한 주소로 사용
- 주소지정 방식이 복잡할수록 EA를 결정하는 시간이 오래 걸린다
EA
- 유효 주소 (Effective Address)
- Data가 저장된 기억장치의 실제 주소
A
- 명령어 내의 주소 필드 내용
- Operand가 기억장치 주소일 경우
R
- 명령어 내의 레지스터 번호
- Operand가 레지스터 번호일 경우
(A)
- 기억장치 A번지의 내용
(R)
- 레지스터 R의 내용
(1) 직접 주소지정 방식 (Direct Addressing Mode)
- Operand의 내용이 실제 Data의 유효주소
- EA = A
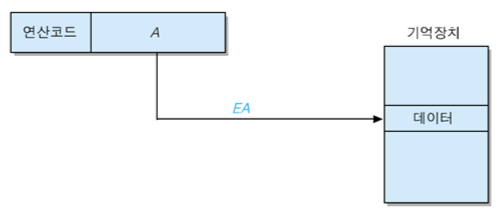
▶ 장점
- Data를 인출 할 때, 기억장치에 1번만 액세스하면 된다
▶ 단점
- 연산코드를 제외하고 남은 비트들만 Operand 비트로 사용할 수 있기 때문에 직접 지정할 수 있는 기억장치 용량이 제한된다
- 이 문제점을 해결 : 간접 주소지정 방식
(2) 간접 주소지정 방식 (Indirect Addressing Mode)
- Operand의 내용(주소 A)가 가리키는 주소가 실제 Data의 유효주소 (주소 A의 주소가 유효주소이다)
- EA = (A)
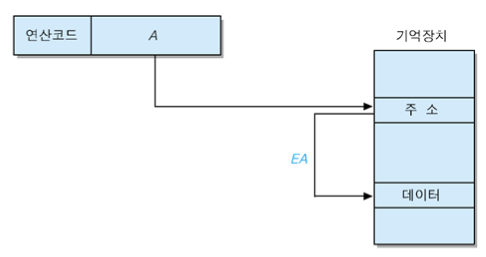
▶ 장점
- 기억장치의 최대 용량이 주소 A가 가리키는 기억장소의 전체 비트 수에 의해 결정된다
- 예시를 보면, 기억장치 최대 용량은 A가 가리키는 기억장치 주소의 전체 비트 수에 의해 결정
- 주소지정이 가능한 기억장치 용량을 확장할 수 있다
- 단어 길이 = n(bit) >> 최대 기억장치 용량 = 2n(byte)
▶ 단점
- 실행 사이클동안 기억장치에 2번 액세스 해야 한다
- 첫번째 : 주소 인출
- 두번째 : 해당 주소가 가리키는 기억장치로부터 실제 Data 인출
※ 간접 비트 (I)

I = 0
- 직접 주소지정 방식 → EA = A
I = 1
- 간접 주소지정 방식 → EA = (A)
(3) 묵시적 주소지정 방식 (Implied Addressing Mode)
- 명령어 실행에 필요한 Data의 위치가 이미 묵시적으로 정해져 있는 방식
- 'SHL' 명령어 : AC 내용을 좌측으로 시프트
- 'PUSH R1' 명령어 : R1 내용을 스택에 저장
▶ 장점
- Operand가 없거나 1개뿐이라서 명령어의 길이가 짧다
▶ 단점
- 종류가 제한적이다
- PUSH / SHL / POP,...
(4) 즉시 주소지정 방식 (Immediate Addressing Mode)
- Operand의 내용이 연산에 즉시 사용될 수 있는 실제 Data이다
- Data 인출 안해도 된다
- 프로그램에서 레지스터/변수 초기값을 상수값으로 설정할 때 주로 사용
- 저장되는 값이 2의 보수로 표현되는 수이면, Operand 필드 가장 왼쪽 비트가 부호비트로 사용
- Data의 범위 (Operand 비트 = n)
- -2n-1 ~ 2n-1 - 1
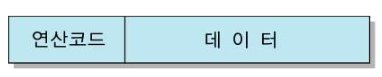
▶ 장점
- Data를 인출하지 않아도 되기 때문에 기억장치에 액세스할 필요가 없다
▶ 단점
- 상수값의 크기가 Operand 필드 비트 수에 의해 제한된다
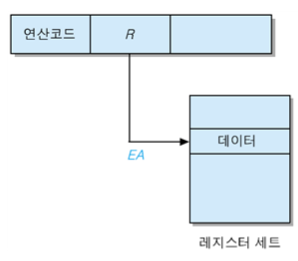
(5) 레지스터 주소지정 방식 (Register Addressing Mode)
- 연산에 사용할 Data가 내부 Register에 저장되어 있는 경우
- Operand가 해당 Register를 가리킨다
- Operand가 가리키는 Register의 내용이 실제 Data
- EA = R
▶ 장점
- Operand 필드의 비트 수가 적어도 된다
- Data 인출을 위해서 기억장치에 액세스할 필요가 없다
▶ 단점
- Data가 저장되는 공간이 CPU 내부 Register로 제한된다
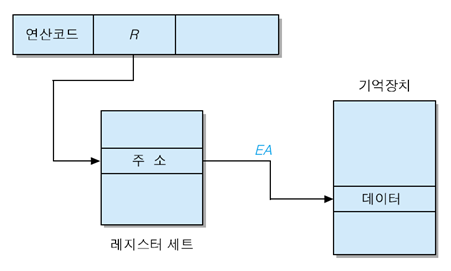
(6) 레지스터 간접 주소지정 방식 (Register-Indirect Addressing Mode)
- Operand가 가리키는 Register의 내용의 주소가 실제 Data의 주소가 된다
- EA = (R)
- Data를 인출하려면 기억장치에 1번 액세스 해야 한다
▶ 장점
- 주소지정을 할 수 있는 기억장치의 용량이 확장된다
- if Register 길이 = 16(bit) ::: 기억장치 용량 = 216 = 64K(byte)
(7) 변위 주소지정 방식 (Displacement Addressing Mode)
- 직접 주소지정 + 레지스터 간접 주소지정
- A = A + (R)
- 사용되는 Register의 종류에 따라 여러 종류의 변위 주소지정 방식 가능
- 2개의 Operand를 가진다
- 하나는 주소 A / 나머지 하나는 레지스터 R
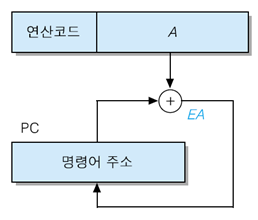
상대 주소지정 방식 (Relative Addressing Mode)
- PC(프로그램 카운터) 사용
- EA = A + (PC)
- A는 일반적으로 2의 보수로 표현
- PC의 내용은 명령어가 실행되면 일단 무조건 해당 명령어의 크기(byte 기준)만큼 증가한다
▶ 장점
전체 기억장치 주소가 명령어에 포함되어야 하는 일반적인 분기 명령어보다 적은 수의 bit만 필요
▶ 단점
- 분기 범위가 Operand 필드의 길이에 의해 제한
- Operand bit들로 표현 가능한 2의 보수 범위
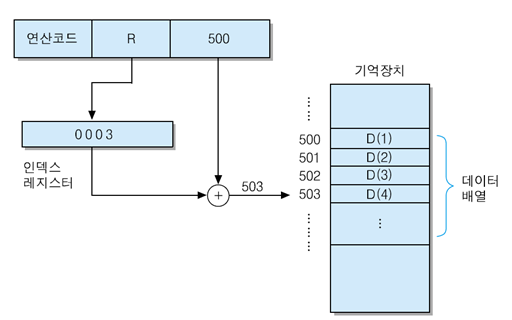
인덱스 주소지정 방식 (Indexed Addressing Mode)
- IX(인덱스 레지스터) 사용
- EA = A + (IX)
- A : 기억장치에 저장된 Data Array의 시작 주소를 가리킨다
- IX : 인덱스(index) 값을 저장하는 특수-목적 Register
- 주로 배열 Data를 액세스할 때 사용한다
- 배열의 다음 Data들을 순차적으로 액세스하려면 IX의 내용만 1씩 증가시키면 된다
- 자동 인덱싱(auto-Indexing) : IX의 내용을 자동적으로 증가/감소 시키기
- 유효 주소가 결정될 때마다 아래 두 연산들이 연속적으로 수행
(1) EA = A + (IX) (2) IX + 1 -> IX
베이스-레지스터 주소지정 방식 (Base-Register Addressing Mode)
- BR(베이스-레지스터) 사용
- EA = A + (BR)
- 주로 프로그램의 위치 지정/변경에 사용
실제 상용 프로세서들의 명령어 형식
CISC (Complex Instruction Set Computer) 프로세서
- 명령어의 수가 많다
- 명령어 길이가 명령어 종류에 따라 다르다
- 주소지정 방식이 매우 다양하다
- PDP 계열 / 인텔 펜티엄 계열
RISC (Reduced Instruction Set Computer) 프로세서
- 명령어의 수를 최소화
- 명령어 길이를 일정하게 고정
- 주소지정 방식의 종류를 단순화
- ATmega microcontroller / ARM 계열
PDP-10 프로세서
- 고정 길이의 명령어 형식 사용
- word 길이 = 명령어 길이 : 36bit
- 연산 코드 : 9bit >> 최대 512 종류의 연산 허용 (실제로는 365개)
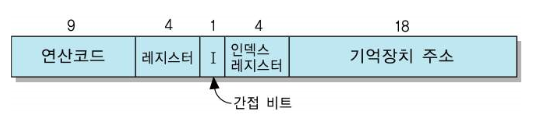
PDP-11 프로세서
- 다양한 길이의 명령어 형식 상요
- 연산 코드 : 4 ~ 16bit
- Operand 개수 : 0, 1, 2개
펜티엄 계열 프로세서
- 기억장치 공간이 segment 단위로 분리되어 액세스
- SR(세그먼트 레지스터)에 의해서 구분
- SR은 6개이고, 각 SR은 해당 segment의 시작주소를 보유
- 펜티엄 계열 프로세서에서는 선형주소를 생성
※ 선형주소 (LA : Linear Address)
- 프로세서가 발생하는 주소
- LA = EA + (SR)
| 주소지정 방식 | 유효 주소(EA) | 선형 주소(LA) |
| 직접 주소지정 | EA = A | LA = A + (SR) |
| 즉시 주소지정 | 데이터 = A | |
| 레지스터 주소지정 | EA = R | LA = R + (SR) |
| 인덱스-레지스터 주소지정 | EA = A + (IX) | LA = A + (IX) + (SR) |
| 베이스-레지스터 주소지정 | EA = A + (BR) | LA = A + (BR) + (SR) |
| 인덱스-R + 베이스-R 주소지정 | EA = A + (IX) + (BR) | LA = A + (IX) + (BR) + (SR) |
| 베이스-레지스터 간접 주소지정 | EA = (BR) | LA = (BR) + (SR) |
| 상대 주소지정 | EA = A + (PC) | LA = A + (PC) |