2022. 5. 14. 14:02ㆍMajor`/인공지능
Supervised Learning
Supervised Learning은 인간이 Label된 Data(input - intput에 대한 output)을 부여하고 Agent는 받은 여러 Example들을 통해서 input에 대한 output이 도출되는 "가설 함수"를 찾아내야 한다
Learning Problem
1. 목적함수 F
F란 input data에 대해서 언제나 반드시 output을 결정할 수 있어야 한다
단, Agent(학습자)는 영원히 F를 모른다
Agent가 Learning을 통해서 얻는 것은 F와 최대한 비슷한 "가설함수 H"를 찾아내는 것이다
2. Example (input - output pair)
Agent는 (input - output pair)로 이루어진 여러개의 Example들을 감독으로부터 부여받게 된다
- (x1, y1) : F(x1) = y1 / (x2, y2) : F(x2) = y3 / (x3, y3) : F(x3) = y3 / (x4, y4) : F(x4) = y4 / .....
Agent는 Example을 받는다고 해서 함수의 수식을 아는 것은 아니다
따라서 Agent는 여러개의 Example들을 통해서 가설함수를 찾아내야 한다
3. N개의 Examples :: Training Set
N개의 "훈련 집합"을 감독이 Agent에게 부여해준다
집합에는 "훈련 집합" / "검증 집합" / "테스트 집합"이 존재한다
훈련 집합은 말그대로 Agent가 학습할 때 사용하는 데이터이다
검증 집합/데이터 집합은 Agent가 학습을 통해서 도출한 가설함수 H를 테스트하는 집합들이다
당연히 훈련집합과 검증 집합/테스트 집합은 서로 달라야 한다
검증 집합을 통해서 가설함수를 검증했을 때 에이전트가 도출한 가설함수의 성능이 안좋을 경우 에이전트는 재학습을 통해서 다시 가설함수를 찾아낼 수 있다
※ N이 클수록
장점 : F와 최대한 비슷한 H를 찾아낼 확률이 높아진다
단점 : 계산량이 굉장히 많아진다. 이말은 곧 학습량이 굉장히 많아진다는 의미이다
4. 가설함수 H
몇가지 Training Set을 통해서 Agent는 결국 가설함수를 찾아내야 한다
여기서 "F = H"가 아니라 "F ≒ H"이다
왜냐하면 Agent(학습자)는 영원히 F를 알 수 없기 때문이다
그리고 Agent는 무한대의 H를 찾아낼 수 있다
여기서 최종적으로 Agent가 결정해야할 H는 결국 F와 최대한 비슷하고, 효율이 가장 좋은 H를 찾는 것이다
몇가지 용어
▶ Test Set (≠ Training Set)
결국 Agent는 "인간이 부여한 N개의 학습 데이터"를 위한 가설함수를 찾아냈다
그런데 N개의 학습 데이터를 위한 가설함수를 찾았다고 끝나는 것은 아니다. 우리가 원하는 것은 N개의 학습 데이터 "이외의 Test Set"에 대해서도 가설함수가 일반화를 잘 할수 있는 것을 원한다
따라서 "학습을 위한 Training Set"과 "검증을 위한 Test Set"은 당연히 달라야 한다
▶ Generalization
"학습 데이터"를 위한 가설함수가 "학습 데이터 이외의 집합"에 대해서 얼마나 잘 적용되는지를 의미한다
결국 Generalization이란 부여하지 않은 새로운 데이터에 대해서 얼마나 출력을 정확히 할 수 있는가이다
▶ Classification
output이 이산화된 데이터일 경우
- 저 사람이 빌게이츠냐 스티븐 잡스냐 일론 머스크냐 ...
- 1등급이냐 2등급이냐 3등급이냐 ....
▶ Regression
output을 분류할 수 없는 경우
- 여기서 "숫자"를 생각할 수 있는데 단순히 숫자라고 해서 "등급, 점수, .."이런 것은 분류가 가능하기 때문에 Regression이라고 할 수 없다
- 주가 / 집값 / ... 이런것들을 Regression이라고 한다
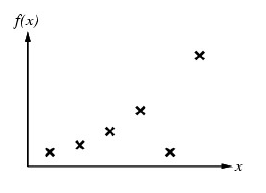
좌표위의 점들이 인간이 Agent에게 부여한 Example(6)라고 하자
여기서 인간이 또 부여해줘야 하는 것이 "범위"이다
만약 좌표상에서 범위가 무한할 경우 Agent는 절대로 해당 값에 대한 근사함수를 찾지 못할 것이다
범위를 제공한다는 의미는 결국 가설함수 H를 찾을 때 가설함수는 다항식 형태이므로 "다항식의 차수"를 제공한다는 것이다
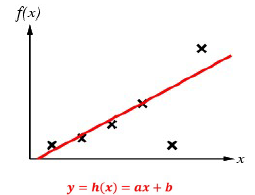
인간이 "ax + b"라는 범위를 제공해주고 에이전트가 학습을 통해서 가설함수를 도출해낸 모습이다.
하지만 모든 훈련 데이터에 대해서 만족하지 않는 것을 볼 수 있다
- 물론 여기서 Agent는 (a, b)를 각각 계속 변경함에 따라서 훈련 데이터에 대한 오차를 줄이도록 찾아냈을 것이다
따라서 Agent가 학습을 통해서 어떠한 가설함수를 찾아냈는데 주어진 훈련 데이터 모두를 만족하지 못할 경우 인간은 "다항식의 차수"를 올려서 다시 제공하고 그에 따라서 Agent는 재학습을 할 것이다
다항식의 차수가 올라간다는 의미는 결국 계수가 많아진다는 뜻이고 이말은 곧 학습/지식의 복잡도가 굉장히 높아진다는 의미이다

새로운 범위를 다시 제공해주고 에이전트가 재학습을 통해서 가설함수를 도출해냈지만 여전히 모든 훈련 데이터에 대해서 만족하고 있지 않다
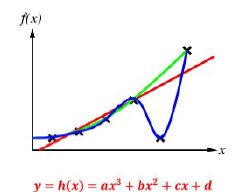
드디어 에이전트가 주어진 훈련 데이터 모두를 만족하는 가설함수를 찾아냈을 것이다
범위가 (a, b) → (a, b, c) → (a, b, c, d)로 증가함에 따라서 Agent의 학습 복잡도는 생각할 수 없을 만큼 복잡했을 것이다
- (a, b, c, d)를 한번에 구하는게 아니라 각각의 계수를 따로따로 오차를 줄이기 위해서 계속 변경
주어진 훈련 데이터 모두를 만족하는 가설함수를 찾아냈을 경우 "가설함수 H가 Consistent하다"라고 말할 수 있다

물론 이런 말도안되게 복잡한 가설함수를 "인간이 계속 범위를 제공해서" 만들수는 있다
하지만 복잡하다고 좋은 가설함수는 아니고 복잡하다는 의미는 시공간적으로 효율성이 그만큼 좋지 않다는 의미이기 때문에 Agent는 "주어진 훈련 데이터를 모두 만족하는 가장 간단한 가설함수 H(Ockham's razor)"를 찾으려고 노력한다
- 차수가 쓸데없이 높으면 {학습 시간 & 학습 데이터}가 굉장히 많이 필요해서 별로 효율이 좋지 않다
결정 트리 (Decision Trees : DT)
결정 트리는 "지식 표현법"중 하나이다
결국 결정 트리를 통해서 "지식"을 도출할 수 있다
- 모든 Decision을 단말 노드에 존재한다
그리고 최적의 결정을 하기 위해서 시공간적 복잡도가 작으면 좋고 이말은 "Tree Size" 최대한 작을수록 좋다는 의미이다
Example) 레스토랑 자리 기다릴지 말지 결정
"결정"을 도와주기 위해서 "여러가지 속성"들이 존재한다
여기서 어떠한 속성을 차례대로 고르냐에 따라서 Tree Size가 커질수도 작아질수도 있다
- Alternate : 다른 대안이 있냐 (T / F)
- Bar : 기다릴만한 바가 있냐 (T / F)
- Fri/Sat : 오늘이 금요일이냐 토요일이냐 (T / F)
- Hungry : 지금 배고픈가 (T / F)
- Patrons : 레스토랑에 지금 얼마나 있나 (None / Some / Full)
- Price : 가격 범위 ($ / $$ / $$$)
- Raining : 비가 오고있는가 (T / F)
- Reservation : 우리가 예약을 했나 (T / F)
- Type : 레스토랑 타입 (French / Italian / Thai / Burger)
- WaitEstimate : 기다리는 추정 시간(0-10 / 10-30 / 30-60 / >60)
따라서 각 속성들에 대해서 가능한 모든 조합의 경우의 수는 26 × 32 × 42 = 9216이다

인간이 Agent에게 준 훈련 데이터 집합은 12개이다
전체 9216개의 Set이 존재하는데 그 중 12개의 Set만 부여한 것이다
기계는 "반드시" 인간이 준 예제에 입각해서 학습을 진행한다

이 결정 트리는 인간/감독이 보유하고 있는 목적 함수 F라고 할 수 있다
결국 Agent는 이 F와 최대한 비슷한 가설함수 H Tree를 찾아내야 한다
그리고 위의 결정 트리에서 알 수 있는 사실은 "결정을 수행할 때 반드시 모든 feature을 이용하는 것은 아니다"라는 사실이다

이것은 위의 결정 트리를 만들기 위한 pseudo code이다
여기서 가장 중요한 포인트는 "CHOOSE-ATTRIBUTE"부분이다
결국 최적의 속성을 골라야 Tree Size가 작아질 것이고 그에 따라서 복잡도가 감소하고 결국 Agent는 모든 훈련 데이터를 만족하는 가장 간단한 가설함수 H(결정 트리)를 생성해낼 것이다
결정트리는 게임중에서 스무고개랑 비슷한 방식이다
스무고개도 결국 "질문"을 잘해야 빨리 끝나듯이 결정 트리도 "속성을 잘 정해야" 트리 사이즈가 작아진다
속성 결정하기
위의 Example에서 속성을 트리의 root node속성을 결정할 때는 "Entropy"라는 개념을 사용한다
Entropy란 혼합도/불순도를 의미하게 된다
어떠한 속성의 각 value들에 대한 output이 얼마나 혼합적인지를 판단하는 것이다
output(T)를 Positive(p), output(F)를 Negative(n)라고 하자
만약 output이 위의 예시와 같이 T/F 이산적으로 나오는게 아니라 3개 이상으로 나올 경우 Entropy는 그냥 항을 추가해서 다음과 같이 계산해주면 된다
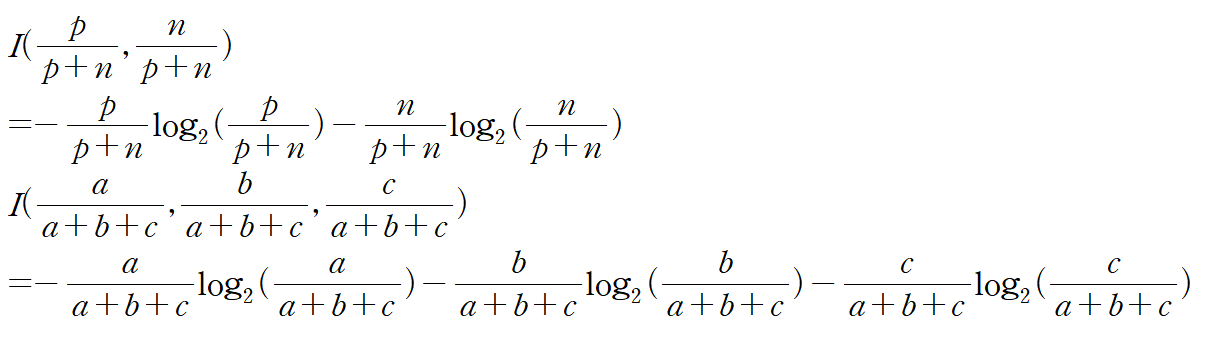
이런식으로 "Information Context(Entropy)"를 구하면 된다
이렇게 각 속성들에 대해서 Entropy를 구하고 나서 최종 속성을 결정하기 위해서 IG라는 값을 계산한다
IG(Information Gain)는 처음 Entropy에 대해서 그 속성을 골랐을 경우 Entropy가 얼마나 감소하는지를 계산한 것이다
따라서 Entropy가 가장 많이 감소된 속성을 결정하는 것이 Best이다
그렇게 root node를 결정하면 그 자식에서도 root를 IG에 의해서 결정해주고 계속해서 나아가면 DT가 생성될 것이다
속성에 대한 value가 T/F로 이루어지지 않은 속성들에 대한 Entropy를 구하면 다음과 같다
Patrons


Patrons의 경우 Entropy가 약 54% 감소했다고 볼 수 있다
Price

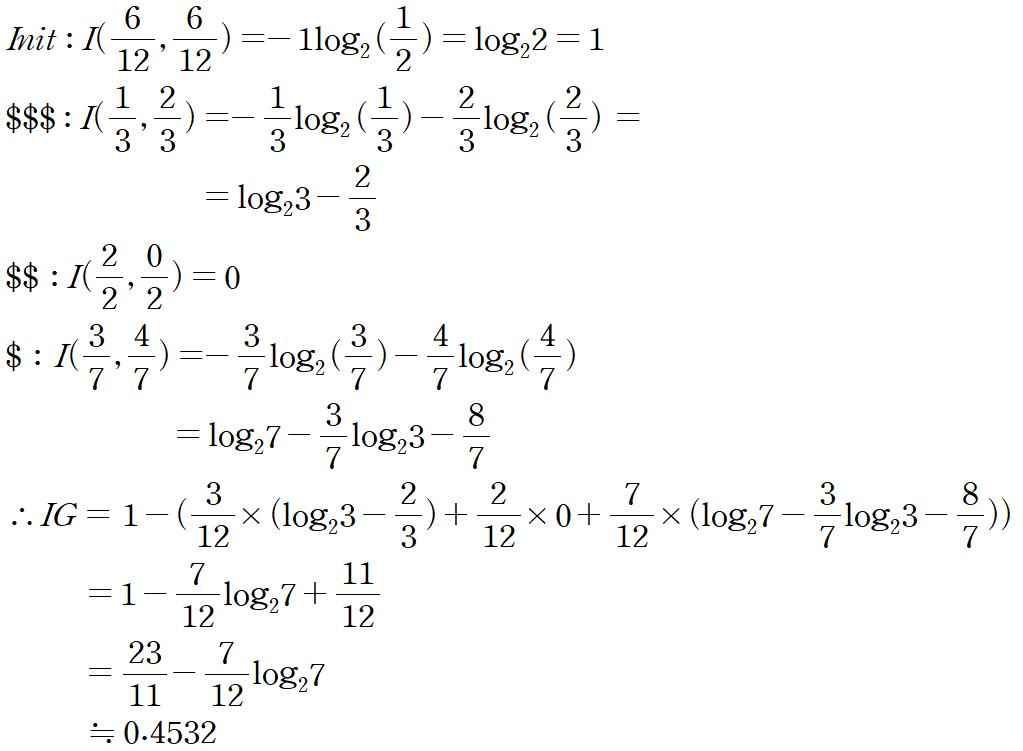
Price의 경우 Entropy가 약 45% 감소했다고 볼 수 있다
Type
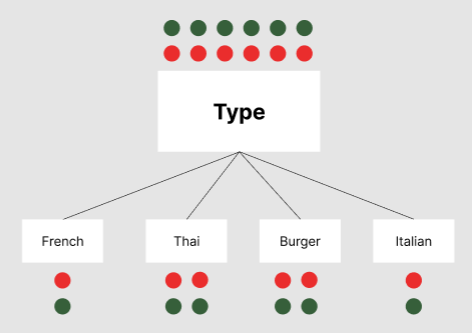
Type의 경우 각 속성의 Entropy가 전부 1이므로 Entropy가 0% 감소했다
WaitingEstimate
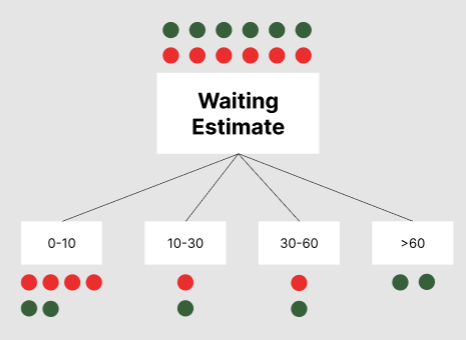
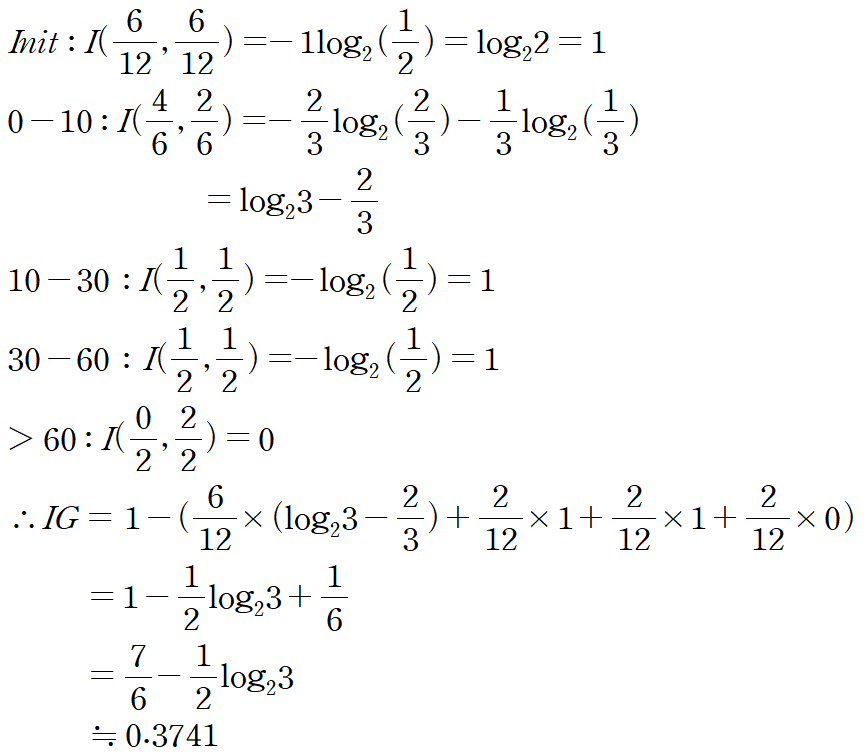
W-Est의 경우 Entropy가 약 37% 감소했다고 볼 수 있다
다른 모든 속성에 대해서 IG를 구했다고 가정하면 "Patrons" 속성이 IG의 값이 가장 높다는 것을 알 수 있다
따라서 root node로는 일단 "Patrons"으로 결정을 한다 (Best Attribute Decision)
이러한 방법으로 Agent가 찾아낸 DT는 다음과 같다

물론 인간이 보유한 DT랑은 약간 다르지만 Agent가 찾아낸 가설 함수(DT)는 인간이 부여한 훈련 데이터에 대해서 모두 만족하는 DT이다
만약 Example을 9216개에 근접해서 준다면 당연히 인간이 보유한 DT랑 거의 유사한 것을 찾아낼 수 있을 것이다.
하지만 훈련 데이터를 많이 주면 정확해지긴 하지만 그만큼 복잡도가 상상할 수 없을 만큼 증가한다
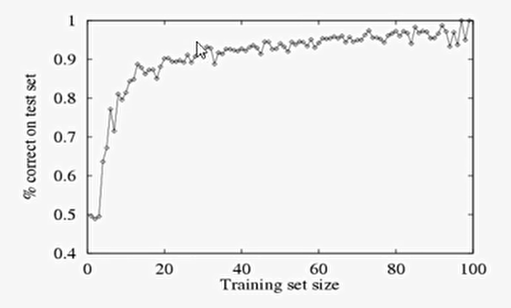
100개까지 학습 데이터를 늘려보았을 때 일반화가 더 잘되는 것을 볼 수 있다
하지만 그만큼 {학습 시간 & 메모리}가 더 많이 필요할 것이다