2022. 7. 5. 12:56ㆍLanguage`/JPA
일반적으로 관계형 DB에서는 객체지향 언어에서 다루는 "상속"이라는 개념이 존재하지 않는다
그대신 "슈퍼타입 - 서브타입"같은 모델링 기법을 통해서 우회적으로 상속을 구현할 수 있다

슈퍼타입 - 서브타입 논리적 모델을 실제 DB에 들어가는 물리적 모델로 구현하는 방법은 총 3가지가 존재한다
- "각각 테이블"로 변환
- "통합 테이블"로 변환
- "서브타입 테이블"로 변환
1. 각각 테이블로 변환 - "조인 전략 (Super Type + Sub Type)"

조인 전략이란 엔티티 각각을 일단 모두 테이블로 만들어준다
그리고 "자식 테이블"은 부모 테이블의 PK를 자신의 PK이자 FK로 사용한다
- 조회할때는 당연히 Join을 많이 사용하게 된다
>> @Inheritance(strategy = InheritanceType.JOINED)
Item (Super Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "item")
@Inheritance(strategy = InheritanceType.JOINED)
public class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "item_id")
private Long id;
private String name;
private Integer price;
}Album (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "album")
public class Album extends Item {
private String artist;
}Movie (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "movie")
public class Movie extends Item {
private String director;
private String actor;
}Book (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "book")
public class Book extends Item {
private String author;
private Integer isbn;
}
※ 생성된 테이블




이처럼 JOIN 전략을 활용하면 Super Type(Item)의 PK가 Sub Type(Album, Movie, Book)의 PK이자 FK가 된 것을 확인할 수 있다
- 컬럼의 순서는 Hibernate에서 제공해주는 "hibernate.hbm2ddl.auto : create"를 사용했기 때문에 무작위로 순서가 정해지는 것이고, 이 순서를 지정해주고 싶으면 DB에서 직접 알맞은 테이블을 생성 후 "hibernate.hbm2ddl.auto : values" 로 테이블 검증을 해주면 된다
@DiscriminatorColumn
여기서 Item은 {album, book, movie}의 Super Type이고 모든 자식들의 instance를 item도 가지고 있어야 한다
그런데 Item의 column을 보면 자식들을 구분해줄 수 있는 특별한 컬럼이 없다
이렇게 자식들을 구분해줄 수 있는 특별한 컬럼을 생성하는 애노테이션이 @DiscriminatorColumn이다

▶ 속성 1 : name
name 속성은 "자식들을 구분해줄 컬럼의 이름"을 설정해주는 속성이다
- 아무것도 설정해주지 않으면 default value로 "DTYPE"이 설정된다
@DiscriminatorColumn
public class Item {...}
@DiscriminatorColumn(name = "hello_dtype")
public class Item {...}
▶ 속성 2 : discriminatorType
discriminatorType은 "자식들을 구분해줄 컬럼의 타입"을 지정해주는 속성이다

[String, Char, Integer]타입 총 3가지가 존재한다
- default type은 String이다
(1) STRING
@DiscriminatorColumn(discriminatorType = DiscriminatorType.STRING)
public class Item {...}Hibernate:
create table item (
DTYPE varchar(31) not null,
item_id bigint not null auto_increment,
name varchar(255),
price integer,
primary key (item_id)
) engine=MyISAM
(2) CHAR
@DiscriminatorColumn(discriminatorType = DiscriminatorType.CHAR)
public class Item {...}WARN: HHH000457: Joined inheritance hierarchy [Inheritance.join.domain.Item] defined explicit @DiscriminatorColumn. Legacy Hibernate behavior was to ignore the @DiscriminatorColumn. However, as part of issue HHH-6911 we now apply the explicit @DiscriminatorColumn. If you would prefer the legacy behavior, enable the `hibernate.discriminator.ignore_explicit_for_joined` setting (hibernate.discriminator.ignore_explicit_for_joined=true)
단순히 discriminatorType.CHAR로 설정을 해주면 위와 같은 에러가 발생하게 된다
<property name="hibernate.discriminator.ignore_explicit_for_joined" value="true" />위의 설정을 persistence.xml에 넣어주던가 아니면 스프링부트를 사용하고 있다면 application.properties에 설정값을 넣어주면 된다
또 다른 해결책으로는 @DiscriminatorValue를 CHAR형태로 설정해주는 것이다
@DiscriminatorColumn(discriminatorType = DiscriminatorType.CHAR)
@DiscriminatorValue("I")
public class Item {...}
@DiscriminatorValue("A")
public class Album extends Item {...}
@DiscriminatorValue("M")
public class Movie extends Item {...}
@DiscriminatorValue("B")
public class Book extends Item {...}이렇게 모든 엔티티에 대해서 @DiscriminatorValue를 CHAR형태로 설정해주면 정상적으로 작동한다
Hibernate:
create table item (
DTYPE char(1) not null,
item_id bigint not null auto_increment,
name varchar(255),
price integer,
primary key (item_id)
) engine=MyISAMCaused by: org.hibernate.AnnotationException: Using default @DiscriminatorValue for a discriminator of type CHAR is not safe
>> 따라서 discriminatorType을 CHAR로 하고싶으면 관련된 모든 엔티티에 @DiscriminatorValue를 적용해줘야 정상작동이 된다
기본적으로 @DiscriminatorValue를 적용해주지 않으면 클래스명 그대로 DTYPE에 들어가기 때문에 CHAR형태에 어긋나게 된다.
따라서 char(1)의 형태에 맞게 각 엔티티의 "별명"을 @DiscriminatorValue로 지정해줘야 한다
Hibernate char discriminator value
Why does hibernate think that char discriminators are not safe? Using default @DiscriminatorValue for a discriminator of type CHAR is not safe
stackoverflow.com
(3) INTEGER
@DiscriminatorColumn(discriminatorType = DiscriminatorType.INTEGER)
public class Item {...}Hibernate:
create table item (
DTYPE integer not null,
item_id bigint not null auto_increment,
name varchar(255),
price integer,
primary key (item_id)
) engine=MyISAMAlbum album = new Album("성시경");
Movie movie = new Movie("조지프 코신스키", "톰 크루즈");
Book book = new Book("김영한", 1);
album.setName("너의 모든 순간");
album.setPrice(10000);
movie.setName("탑건");
movie.setPrice(10000);
book.setName("JPA");
book.setPrice(30000);
em.persist(album);
em.persist(movie);
em.persist(book);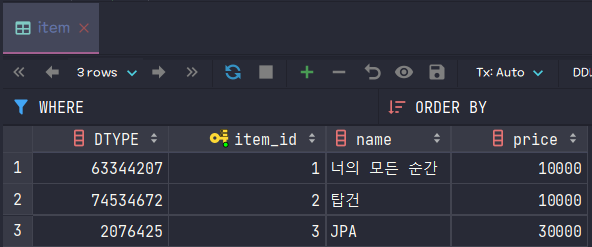
INTEGER로 TYPE을 지정하면 각 서브 엔티티마다 "고유한 값"이 랜덤하게 할당되고 이 값을 기준으로 자식 컬럼들을 비교한다

추가적인 값들을 넣어도 DTYPE의 "고유 INTEGER 값"으로 [Album, Book, Movie]를 구별할 수 있다
▶ 속성 3 : columnDefinition
columnDefinition은 말그대로 DTYPE의 컬럼 속성 설정을 직접 해줄수 있는 것이다
- default 설정은 varchar(31) not null이다
@DiscriminatorColumn(columnDefinition = "varchar(180)")
public class Item {...}Hibernate:
create table item (
DTYPE varchar(180) not null,
item_id bigint not null auto_increment,
name varchar(255),
price integer,
primary key (item_id)
) engine=MyISAM기본적으로 DTYPE은 반드시 NOT NULL이여야 하므로 columnDefinition에서 따로 NOT NULL지정을 해주지 않아도 알아서 NOT NULL로 세팅이 된다
▶ 속성 4 : length

length속성은 discriminatorType이 STRING일 경우에만 적용할 수 있는 속성이다
이는 DTYPE의 길이를 지정해줄 수 있고, default value는 "31"이다
(1) 기본값
@DiscriminatorColumn
public class Item {...}Hibernate:
create table item (
DTYPE varchar(31) not null,
item_id bigint not null auto_increment,
name varchar(255),
price integer,
primary key (item_id)
) engine=MyISAM
(2) 설정값
@DiscriminatorColumn(length = 77)
public class Item {...}Hibernate:
create table item (
DTYPE varchar(77) not null,
item_id bigint not null auto_increment,
name varchar(255),
price integer,
primary key (item_id)
) engine=MyISAMdiscriminatorType은 기본값이 STRING이므로 위에서 따로 설정해주지 않아도 lenght가 정상적으로 적용됨을 확인할 수 있다
@PrimaryKeyJoinColumn
생성된 서브타입들의 테이블을 보게되면 전부 슈퍼타입인 Item의 PK(item_id)를 그대로 가져온것을 확인할 수 있다
여기서 각 서브타입마다 PK Name을 변경하고 싶다면 @PrimaryKeyJoinColumn을 활용하면 된다
@PrimaryKeyJoinColumn(name = "album_id")
public class Album extends Item {
private String artist;
}
@PrimaryKeyJoinColumn(name = "book_id")
public class Book extends Item {
private String author;
private Integer isbn;
}
@PrimaryKeyJoinColumn(name = "movie_id")
public class Movie extends Item {
private String director;
private String actor;
}


이제 원하는대로 각 서브타입 테이블마다 서로 다른 PK Name을 가지게 되었다
@DiscriminatorValue
이제 Book, Album, Movie에 대한 데이터를 저장해보고 그에 따라서 생성되는 instance를 확인해보자
Album album = new Album("성시경");
album.setName("너의 모든 순간");
album.setPrice(10000);
Book book = new Book("김영한", 123);
book.setName("JPA");
book.setPrice(20000);
Movie movie = new Movie("조지프 코신스키", "톰 크루즈");
movie.setName("탑건");
movie.setPrice(5000);
em.persist(album);
em.persist(book);
em.persist(movie);



분명 album, movie, book에 대해서만 persist를 하였는데 item에도 자연스럽게 insert가 된 것을 확인할 수 있다
>> JOIN 전략에서는 Sub Type에 대한 insert가 발생하면 자연스럽게 Super Type에도 insert가 발생해서 "총 2번의 insert"가 발생된다
// em.persist(movie) 예시
Hibernate:
/* insert Inheritance.join.domain.Movie
*/ insert
into
item
(name, price, divide_column)
values
(?, ?, 'Movie')
Hibernate:
/* insert Inheritance.join.domain.Movie
*/ insert
into
movie
(actor, director, movie_id)
values
(?, ?, ?)
그리고 Item 테이블을 보게되면 각 서브 타입이 위에서 설정해준 "@DiscriminatorColumn(name = "divide_column")"로 인해 구분이 되는 것을 확인할 수 있다
여기서 저장되는 기본값은 "엔티티 이름"이고 이를 변경하고 싶다면 @DiscriminatorValue로 원하는 값으로 저장되도록 할 수 있다
@DiscriminatorValue("A")
public class Album extends Item {
private String artist;
}
@DiscriminatorValue("B")
public class Book extends Item {
private String author;
private Integer isbn;
}
@DiscriminatorValue("M")
public class Movie extends Item {
private String director;
private String actor;
}
JOIN 전략의 장점 & 단점
<장점>
- 테이블이 정규화된다
- FK 참조 무결성 제약조건을 활용할 수 있다
- 저장공간을 효율적으로 사용한다
<단점>
- 조회할 때 JOIN이 많이 사용되기 때문에 어쩔수없이 성능이 저하될 수 있다
- 조회 쿼리가 복잡하다
- 데이터를 등록할 때 insert query가 2번 나가게된다
2. 통합 테이블로 변환 - "단일 테이블 전략"

단일 테이블 전략은 말그대로 Sub Type의 모든 Column들을 Super Type에 몰아넣고, Super Type에서는 각 instance들에 대해서 @DiscriminatorColumn으로 구분한다
당연히 하나의 테이블에 다 몰아넣었기 떄문에 Join이 별도로 필요하지 않고 일반적으로 조회 성능이 가장 빠르다(물론 무조건은 아니다)
>> @Inheritance(strategy = InheritanceType.SINGLE_TABLE)

상속의 기본 전략은 SINGLE_TABLE이므로 @Inheritance 내부에 별도로 strategy를 설정해주지 않으면 알아서 default값인 SINGLE_TABLE로 설정된다
Item (Super Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "item")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn
public class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "item_id")
private Long id;
private String name;
private Integer price;
}Album (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@DiscriminatorValue("A")
public class Album extends Item {
private String artist;
}Book (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "book")
public class Book extends Item {
private String author;
private Integer isbn;
}Movie (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "movie")
public class Movie extends Item {
private String director;
private String actor;
}>> SINGLE_TABLE전략에서 Sub Type(Album, Movie, Book)들은 테이블로 매핑될 필요가 없기 때문에 @Table 애노테이션을 지워줘도 된다
※ 생성된 테이블

Super Type인 Item Table에 모든 Sub Type Column이 모이고, 이를 구분할 수 있는 DTYPE Column이 생성됨을 확인할 수 있다
Album album = new Album("성시경");
album.setName("너의 모든 순간");
album.setPrice(10000);
em.persist(album);
Book book = new Book("김영한", 123);
book.setName("JPA");
book.setPrice(20000);
em.persist(book);
Movie movie = new Movie("조지프 코신스키", "톰 크루즈");
movie.setName("탑건");
movie.setPrice(5000);
em.persist(movie);Hibernate:
/* insert Inheritance.single.domain.Album
*/ insert
into
item
(name, price, artist, DTYPE)
values
(?, ?, ?, 'A')
Hibernate:
/* insert Inheritance.single.domain.Book
*/ insert
into
item
(name, price, author, isbn, DTYPE)
values
(?, ?, ?, ?, 'B')
Hibernate:
/* insert Inheritance.single.domain.Movie
*/ insert
into
item
(name, price, actor, director, DTYPE)
values
(?, ?, ?, ?, 'M')
SINGLE_TABLE 전략의 장점 & 단점
<장점>
- 조인이 필요없기 때문에 일반적으로는 조회 성능이 빠르다
- 조회 쿼리가 단순하다
<단점>
- 자식 엔티티가 매핑한 컬럼은 전부 NULL을 허용해야 한다
- 단일 테이블에 모든것을 저장하기 때문에 테이블 크기가 매우 커지고 이러한 이유때문에 오히려 조회 성능이 느려질 수 있다
<특징>
- 구분 컬럼 : @DiscriminatorColumn을 반드시 사용해야 한다
3. 서브타입 테이블로 변환 - "구현 클래스마다 테이블 전략"

구현 클래스마다 테이블을 만드는 전략은 Item 이라는 Super Type을 구현한 각 Sub Type마다 테이블을 만들어주는 전략이다
이는 Super Type의 Column들을 각 Sub Type에게 뿌려주는 것이다
>> @Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
그리고 TABLE_PER_CLASS 전략에서 Super Type은 실제로 사용되지 않기 때문에 "abstract class"로 만들어줘도 된다
추가적으로 상속 전략을 TABLE_PER_CLASS로 할 경우 Super Type의 PK 전략은 IDENTITY가 아닌 TABLE/AUTO로 설정해줘야 오류가 발생하지 않는다
-> Cannot use identity column key generation with <union-subclass> mapping for
[hibernate] <union-subclass> (TABLE_PER_CLASS)와 함께 ID 열 키 생성을 사용할 수 없습니다. - 리뷰나라
com.something.SuperClass : @Entity @Inheritance(strategy = InheritanceType.TABLE_PER_CLASS) public abstract class SuperClass implements Serializable { private static final long serialVersionUID = -695503064509648117L; long confirmationCode; @Id @GeneratedV
daplus.net
Item (Super Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@DiscriminatorColumn
public abstract class Item {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "item_id")
private Long id;
private String name;
private Integer price;
}Album (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "album")
public class Album extends Item {
private String artist;
}Book (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "book")
public class Book extends Item {
private String author;
private Integer isbn;
}Movie (Sub Type)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "movie")
public class Movie extends Item {
private String director;
private String actor;
}
※ 생성된 테이블



Album album = new Album("성시경");
album.setName("너의 모든 순간");
album.setPrice(10000);
Book book = new Book("김영한", 123);
book.setName("JPA");
book.setPrice(20000);
Movie movie = new Movie("조지프 코신스키", "톰 크루즈");
movie.setName("탑건");
movie.setPrice(5000);
em.persist(album);
em.persist(book);
em.persist(movie);


언뜻보면 굉장히 좋은 전략인것 같지만 일반적으로는 추천하지 않고 실무에서는 거의 사용하지 않는다
TABLE_PER_CLASS 전략의 장점 & 단점
<장점>
- 서브 타입을 구분해서 처리할 때 효과적이다
- NOT NULL 제약조건을 사용할 수 있다
<단점>
- 여러 자식 테이블을 함께 조회할 때 SQL-UNION을 사용해야 하기 때문에 성능이 느리다
- 자식 테이블을 통합해서 쿼리하기 힘들다
<특징>
- 구분 컬럼이 존재하지 않는다
>> 따라서 기본 전략은 JOINED을 활용하고 굉장히 간단하고 변할 일이 거의 없을 때는 SINGLE_TABLE 전략을 활용해도 된다