2022. 5. 14. 11:56ㆍMajor`/인공지능
Learning
AI에서 학습은 단지 무엇을 배운다고 끝나는 것이 아니다
배운다는 경험을 토대로 에이전트의 작업 성능이 개선이 되어야 그 에이전트는 "학습 능력이 존재"한다고 볼 수 있다
이러한 점은 인간도 마찬가지이다
아무리 가르쳐줘도 발전이 없는 사람은 학습 능력이 전혀 없는 사람이라고 볼 수 있다
반면에 가르쳐줄수록 경험이 쌓이고 그에 따른 성능이 개선되는 사람은 학습 능력이 있다고 볼 수 있다
학습의 필요성
1. 설계자는 미래에 일어날 모든 가능한 상황과 변화에 대해서 에이전트를 처음 설계할 때는 예상할 수 없다
- 따라서 Agent에게 학습은 필수적이다. 학습을 통해서 설계자가 예상하지 못한 이벤트에 대해서 대처할 수 있는 능력을 만들어야 한다
2. 프로그래머도 사람이기 때문에, 어떠한 상황에 대해서 최적의 행동이 무엇인지 모를때가 존재한다
3. Agent는 학습을 통해서 더 완벽한 시스템을 구축할 가능성이 존재한다
결국 "학습"을 통해서 Agent는 자신의 "의사/행동 결정 구조"를 변경시킨다

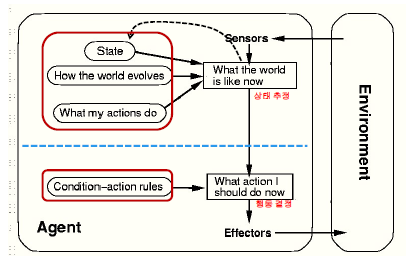


{Simple Reflex & Model-Based Reflex} Agent들은 "Condition-Action Rules"에 의해서 행동이 결정된다.
따라서 이러한 Agent들은 Learning을 통해서 "Condition-Action Rules"을 modify해나간다
{Model-Based Reflex & Goal-Based & Utility-Based} Agent들은 여러 요소들을 종합해서 최종 행동을 결정한다
- Model-Based Reflex : State / World Model / Action Model / Condition-Action Rules
- Goal-Based Agent : State / World Model / Action Model / Goals
- Utility-Based Agent : State / World Model / Action Model / Utility
- Action Model : 내가 할 수 있는 행동은 무엇일까
- World Model : 행동을 하면 세상이 어떻게 변할까
여기서 World Model / Action Model을 modify해나가면, 결국 센서로부터 인식하는 state도 더 좋은 방향으로 인식이 되고 그에 따라서 더 최적의 행동을 결정할 수 있을 것이다
- 단, 외부에서 직접 개입해서 요소들을 변경해주는 것은 "Learning"이 아니다. Learning이란 Agent "스스로" 하는 것이다
데이터 & 지식 표현법
결국 Learning을 한다는 의미는 "새로운 지식"을 습득한다는 의미이다.
새로운 지식을 습득함에 따라 행동 결정 구조를 modify하고 더 나은 행동을 앞으로 결정할 수 있다
학습을 더 내부적으로 들어가보면 결국 Agent는 "학습 데이터"를 먼저 외부로부터 부여받게 된다. 이 "학습 데이터"를 통해서 Agent는 Learning을 하고 Learning의 결과로 "새로운 지식"을 얻게 된다
- input : 학습 데이터
- output : 새로운 지식
결국 여러가지 구체적인 사례(학습 데이터)를 통해서 전부를 수용할 수 있는 일반화된 지식(새로운 지식)을 얻는 "귀납적 Learning"을 하게 된다
여기서 개발자는 input - output 중간의 Process/Algorithm을 개발해줘야 한다
그리고 이 Process를 개발하기 위해 필요한 것들은 {input이 어떤 형태로 들어오고 & output은 어떤 형태로 출력해야 하는가}를 고려해야 한다
데이터 표현법
속성 값들의 Vector(:: Set?)로 표현할 수 있다
- (111, "홍길동", 20, "컴퓨터과학과")
지식 표현법
논리적 문장으로 표현할 수 있다
지식 표현법이 가장 중요한 부분이다
- on(A, B) / before(X, Y) :- after(Y, X)
- 확률 그래프 (베이지안 네트워크)
- 인공 신경망
- 결정 트리
- ...
학습 타입
1. 사전 지식에 의존하는 학습
사전 지식이란 Agent가 학습을 할 때 미리 알고있어야 하는 여러 지식들을 뜻한다
학습을 하기 전에 Agent가 무슨 지식을 얼마나 가지고 있느냐에 따라서 학습 진행 방법이 달라진다
※ 귀납적 학습 (Inductive Learning)
다수의 구체적 사례들을 통해서 일반화된 지식을 생성
- 여러가지 Example(input - output)을 통해서 일반적 지식/규칙을 학습
※ 연역/분석적 학습 (Deductive/Analytical Learning)
일반화된 지식/규칙들을 통해서 구체적인 사례/지식/규칙을 학습
>> 구체적 사례가 많은 경우 : 귀납적 학습 / 일반적 지식이 많은 경우 : 연역적 학습
2. 피드백에 의존하는 학습
※ 교사/감독 학습 (Supervised Learning)
인간이 여러 "학습 데이터"를 부여해주고 Agent는 부여받은 학습 데이터를 통해서 Learning을 진행한다
- Supervised Learning에서의 학습 데이터는 Labeled Data라고도 불린다 :: input에 대해서 output도 같이 부여
- 따라서 Agent는 학습 데이터의 각 input에 대해서 output을 도출해낼 수 있어야 학습을 완료했다고 할 수 있다
output이 "Discrete"하다면 "Classification(분류)"이라고 부른다



- 지진이나 핵실험이냐 / 회원 등급화 / ...
output이 "Continuous"하다면 "Regression(회귀)"이라고 부른다


- 집값 예측 / 주가 예측 / ....



※ 비교사/무감독 학습 (Unsupervised Learning)
"학습 데이터"를 부여하기는 하지만 input에 대한 output은 부여하지 않는다 :: input value만 부여
따라서 input에 대한 output이 존재하지 않기 때문에 에이전트는 Learning을 통해서 "비슷한 input끼리 그룹화를 시키게 된다" :: Clustering(군집화)

※ 강화 학습 (Reinforcement Learning)
이 경우는 인간이 어떠한 학습에 대해서 Example을 주는것이 아니라 그냥 에이전트를 야생에 내보내서 직접 스스로 학습하라는 경우이다
- 학습에 대한 "목표"가 존재하지 않는 학습
물론 에이전트가 야생에 나가서 어떠한 Action을 취하고 그에 따른 결과를 얻었을 때 인간은 "결과에 대한 보상"을 에이전트에게 지급해준다
그리고 에이전트가 수행한 action에 대해서 환경이 변화되면 "변경된 환경"에 대해서도 Agent에게 알려준다

이러한 Sequence가 존재한다고 하자
Agent가 현재 환경(s1)에서 어떠한 Action(a1)을 수행했고 인간은 거기에 대한 보상으로 "+5"를 지급했다고 하자
| state | action | reward |
| s1 | a1 | +5 |
그 다음에 Agent는 현재 환경(s2)에서 Action(a2)를 수행했고 인간은 거기에 대한 보상으로 "+1"을 지급했다고 하자
| state | action | reward |
| s1 | a1 | +5 |
| s2 | a2 | +1 |
여기서 환경이 다시 s1으로 바뀌었다
이제 에이전트는 이전에 s1상태에서 a1을 수행했기 때문에 그대로 똑같은 action을 할 수도 있고 아니면 다른 action을 수행할 수도 있다
- Exploitation Issue : 동일한 상태에서 이전에 수행했던 action 다시 수행
- Exploration Issue : 동일한 상태에서 이전에 수행하지 않았던 새로운 action 수행
>> 여기서 Exploitation은 영원히 다른 action에 대한 reward를 알 방법이 없다. 따라서 Exploration을 통해서 탐험을 할 때도 있어야 한다
이러한 Issue들을 고려해서 에이전트는 현재 환경(s1)에 대해서 새로운 Action(a2)를 수행했더니 인간은 "-1"을 지급해주었다
| state | action | reward |
| s1 | a1 | +5 |
| s2 | a2 | +1 |
| s1 | a2 | -1 |
여기서 에이전트가 깨달은 것이 있을 것이다
s1상태에 대해서 a1의 보상이 a2의 보상보다는 좋으니 s1상태에 대해서는 a2라는 행동은 이제 수행하지 않을 것
둘끼리 비교해도 더 나은 행동이 존재하기 때문에 안좋은 행동은 하지 않을 거라고 생각하는 에이전트가 Rational Agent일 것이다