2021. 11. 6. 14:19ㆍCertificate`/SQLD
그룹함수 (Group Function)
- 하나의 SQL로 테이블을 1번만 읽어서 빠르게 원하는 자료 작성 가능
- 소계/합계 표시를 위한 GROUPING함수/CASE함수를 통해 쉽게 원하는 포맷의 보고서 작성 가능
- ROLLUP 함수 : 집계 함수를 제외하고, 소그룹 간의 소계 계산
- CUBE 함수 : GROUP BY 항목들 간 다차원적인 소계 계산
- GROUPING SETS 함수 : 특정 항목에 대한 소계 계산
ROLLUP 함수
- 집계 함수를 제외하고, 소그룹 간의 소계 계산
- 병렬로 수행이 가능하기 때문에 매우 효과적
- 시간/지역처럼 계층적 분류를 포함하고 있는 데이터의 집계에 적합
- GROUP BY절과 같이 사용
- ROLLUP 인수 순서가 바뀌면 결과도 바뀐다 / 소계와 합계를 순서에 맞게 반환
- ROLLUP에 지정된 그룹핑 컬럼의 list는 Subtotal을 생성하기 위해 사용
-> 그룹핑 컬럼 수 = N -> N+1 레벨의 Subtotal 생성 (각 그룹핑 간의 합계 Subtotal)
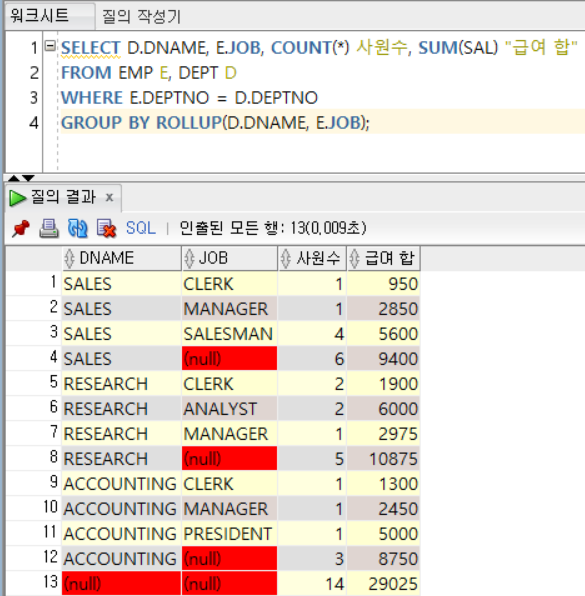
※ ROLLUP의 원리

- 괄호로 묶으면 하나의 컬럼으로 간주하고, 괄호 내 각 컬럼별 집계를 구하지 않는다
※ 부서명, 업무명을 기준으로 사원수와 급여 합을 집계



CUBE 함수
- GROUP BY 항목들 간 다차원적인 소계 계산
- 결합 가능한 모든 값에 대하여 집계 생성
- 장점 : 다양한 데이터를 얻는다
- 단점 : 시스템에 부하를 많이 준다
- 내부적으로 그룹핑 컬럼의 순서를 바꿔서 또 1번의 Query를 추가 수행 / 시스템의 연산 대상이 많다
- 그룹핑 컬럼 수 = N -> 2^N승 레벨의 Subtotal 생성
- CUBE 인수의 순서가 바뀌어도 결과는 같다 / 계산 가능한 모든 소계와 합계 반환
※ 부서명, 업무명을 기준으로 사원수와 급여 합을 집계


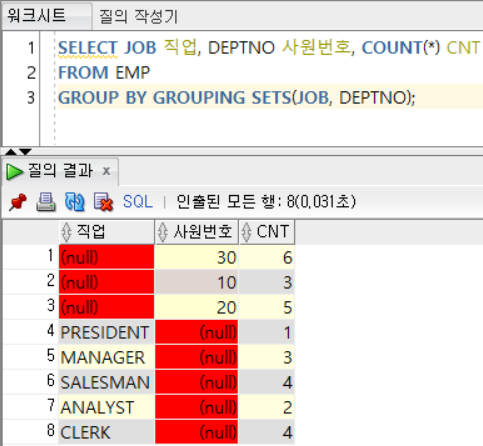
GROUPING SETS 함수
- 지정한 인수들에 대한 개별 집계
- 인수 순서가 바뀌어도 결과는 같다
- 여러 그룹핑 쿼리를 UNION ALL한 결과와 같다



GROUPING / GROUPING_ID 함수
- 소계로 집계되어 출력된 행을 구분
≫ GROUPING 함수
- 매개변수가 1개만 존재
- 해당 컬럼 값이 NULL이면 1, 아니면 0 리턴
- GROUPING 함수에서 사용될 컬럼은 반드시 GROUP BY 절에 명시
- GROUPING SETS를 사용해서 생긴 NULL 컬럼만 구별
- 실제데이터의 NULL은 0 리턴 / 소계 산출로 생성된 행의 NULL은 1 리턴
≫ GROUPING_ID 함수
- 여러개의 매개변수 입력 가능
- 2진수 계산을 통해서 결과 리턴
- 실제데이터의 NULL은 0 리턴 / 소계 산출로 생성된 행의 NULL은 1 리턴
※ Example


※ 01→0001(2진수)→1(10진수)
※ 11→0011(2진수)→3(10진수)


※ 001→0001(2진수)→1(10진수)
※ 011→0011(2진수)→3(10진수)
※ 111→0111(2진수)→7(10진수)
