2021. 10. 18. 20:11ㆍMajor`/DB

정규화 (Normalization)
- 주어진 릴레이션 스키마가 잘못되어 이상현상이 발생하는 릴레이션 스키마를 분해하여, 이상현상이 발생하지 않는 바람직한 릴레이션 스키마로 만들어 가는 과정
- 이상 현상이 발생하지 않도록, 릴레이션을 관련 있는 속성들로만 구성하기 위해 릴레이션을 분해하는 과정
- 함수적 종속성을 판단하여 정규화를 수행
정규화의 목적
- 불필요한 데이터를 제거, 데이터의 중복 최소화
- DB 구조 확장 시, 재디자인을 최소화
- 다양한 관점에서의 query를 지원하기 위해
- 무결성 제약조건의 시행을 간단하게 하기 위해
- 각종 이상 현상을 방지하기 위해, 테이블의 구성을 논리적이고 직관적으로 한다
정규화의 필요성
- 저장공간 최소화
- 데이터 중복에 따른 데이터 불일치성 최소화
- 데이터의 삽입, 수정, 삭제에 따른 이상현상 제거
이상 현상 (Anomaly)
- 관계형 DB 스키마가 잘못 설계되었을 때 나타날 수 있는 부작용
- 관련 없는 속성들을 하나의 릴레이션에 모아 두고 있기 때문에 이상 현상이 발생한다
- 삽입 이상 (Insert) : 투플 삽입 시, 불필요한 데이터를 함께 저장해야만 투플 삽입이 가능한 현상
- 수정 이상 (Update) : 데이터 수정 시, 중복된 데이터의 일부만 수정되어 데이터의 불일치 문제가 발생하는 현상
- 삭제 이상 (Delete) : 투플 삭제 시, 다른 필요한 정보까지 함께 삭제되는 데이터 손실의 문제
함수 종속성 (FD, Functional Dependency)
- X와 Y를 임의의 속성들의 집합이라고 할 때, X의 값이 Y의 값을 유일하게 결정(X의 값에 대해 반드시 한 개의 Y값이 대응)한다면, "X는 Y를 함수적으로 결정한다"라고 한다
- X -> Y로 표기하고, "Y는 X에 함수적으로 종속된다" / "X는 Y의 결정자(Determinant)" / "X는 Y를 결정한다" / "Y는 X에 의해 결정된다"라고 한다

※ Example
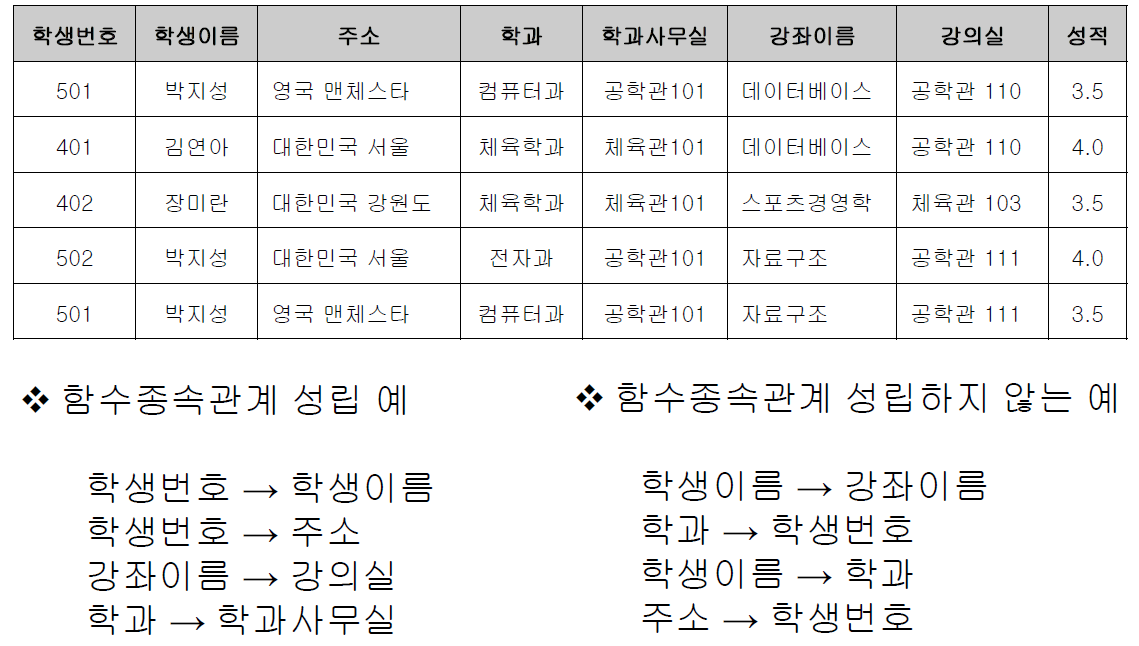
함수 종속성 다이어그램 (Functional Dependency Diagram)
- 릴레이션 속성 : 직사각형
- 속성 간의 함수 종속성 : 화살표
- 복합 속성 : 직사각형으로 묶어서 그림
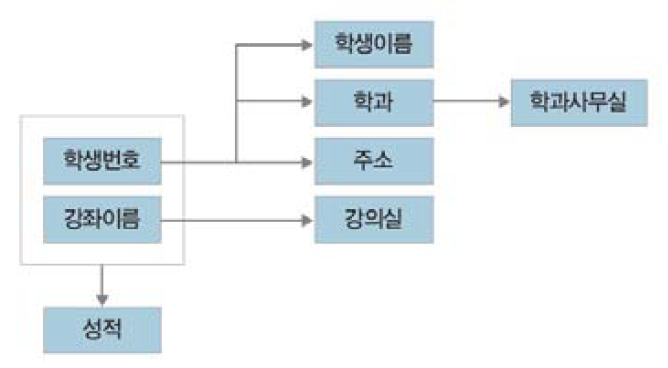
함수 종속 관계 판단 유의사항
- 함수 종속성은 릴레이션의 가능한 모든 인스턴스에 대해 성립해야 한다
- 함수 종속성과 키
- 릴레이션 R에서 속성 X가 후보키 or 기본키이면, R의 모든 속성 Y에 대해 X -> Y가 성립한다 : 키는 릴레이션의 모든 속성에 대해 결정자이다
- 그러나, 함수 종속 X -> Y의 경우 : 속성 X가 반드시 키라는 것을 요건으로 하지 않는다
- (1) 속성 X가 후보키 or 기본키라면 R의 모든 속성 Y에 대해 (2) X -> Y가 성립하지만, 그 반대는 성립하지 않는다
- (1) -> (2)는 성립하지만, (2) -> (1)은 성립하지 않는다
※ Example
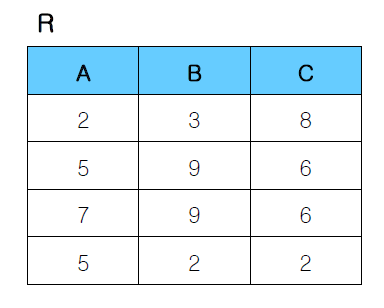
[함수 종속성]
1. A -> B : X (5에 대해 2개의 값(2, 9)이 대응하기 때문)
2. B -> C : O
3. (B, C) -> A : X (9,6에 대해 2개의 값(5, 7)이 대응하기 때문)
4. (A, B) -> C : O
정규형
- 릴레이션의 정규화된 정도(등급)
- 이상현상이 있는 릴레이션은 이상현상을 일으키는 함수 종속성의 유형에 따라 등급 구분
- 정규형 차수가 높을수록 이상현상은 줄어든다
정규화의 원칙
- 정규화 = 스키마 변환 (S -> S`)
1. 무손실 표현
- 같은 의미의 정보 유지
- 더 바람직한 구조
2. 데이터 중복성 감소
3. 릴레이션 분해
- 1개의 릴레이션을 여러 개의 릴레이션으로 표현
- 릴레이션 각각에 대해 독립적 조작이 가능
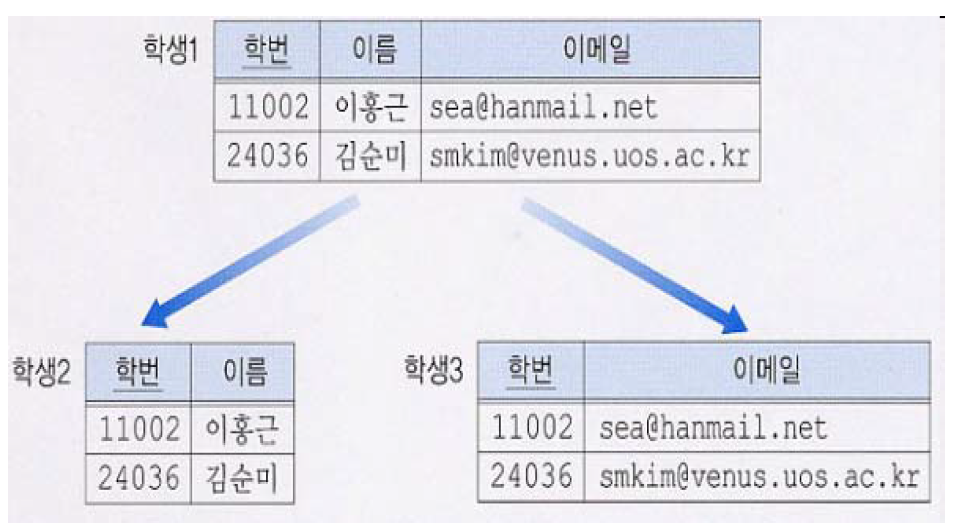
릴레이션 분해 (릴레이션 R)
- 새 릴레이션들은 R의 속성 중 일부씩만 가진다 (R에 없던 속성은 가지지 않는다)
- R의 속성들은 모두 새 릴레이션 중 어느 하나에는 나타난다.
- R(S, N, L, R, W, H) => R1(S, N, L, R, H) / R2(R, W)
릴레이션 분해 : 고려할 점
- 주어진 스키마에 문제가 있어서 나누기를 할 때, 다음 특성을 가져야 한다
- 가짜 투플을 만들지 않는 나누기
- 함수 종속성을 유지하는 나누기
- 불필요하게 자료를 되풀이하지 않는 나누기
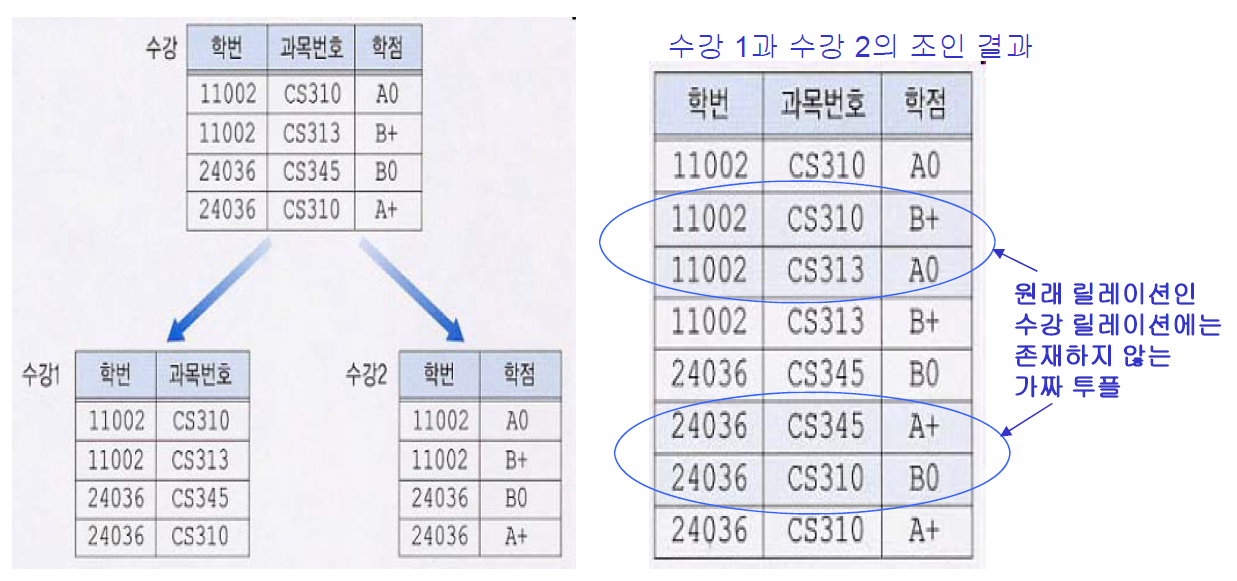
릴레이션 분해 : 무손실-조인 분해 (Lossless Join Decompositions)
- FD집합 F를 만족하는 모든 인스턴스 r에 대해 다음이 성립하면, 릴레이션 R을 릴레이션 X와 Y로 분해하는 것이 F에 대해 '무손실-조인'이라고 한다
- 함수 종속 U -> V가 릴레이션 R에 대해 성립할 때, R을 UV로 이루어진 릴레이션 R1과, R-V로 이루어진 릴레이션 R2로 분해하면 무손실-조인 분해가 된다
※ Example : 릴레이션 R의 속성 (S, N, L, R, W, H)에 함수 종속 관계 R -> W가 존재
- R1(R, W) / R2(S, N, L, R, H)로 분해
정규형 종류

1. 제1 정규형 (1NF)
- 모든 속성 값이 원자 값만으로 된 릴레이션
- 관계형 모델의 릴레이션이라면 모두 제1 정규형(1NF)을 만족한다
※ Example
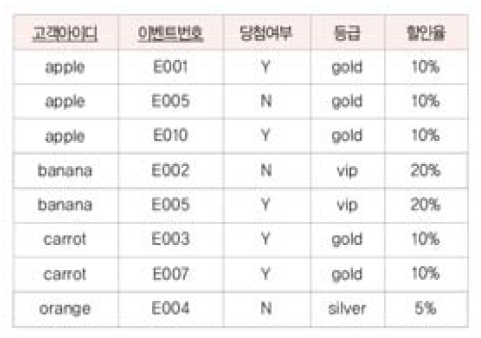
- 함수 종속 : 고객 아이디 -> 등급 / 고객 아이디 -> 할인율 / 등급 -> 할인율 / (고객 아이디, 이벤트 번호) -> 당첨 여부 / (고객 아이디, 이벤트 번호) -> 등급 / (고객 아이디, 이벤트 번호) -> 할인율
- 이상현상
- 삽입 이상 : 신규 고객을 추가할 경우, '이벤트 번호'에 가짜 값을 넣어야 삽입이 가능하다
- 수정 이상 : 'apple' 고객 등급이 gold에서 vip로 변경할 시, 일부 투플만 수정된다 (데이터 불일치 문제 발생)
- 삭제 이상 : 'orange' 고객이 이벤트 참여를 취소하여 관련 투플 삭제 시, 이벤트 참여와 관련 없는 고객 아이디, 등급, 할인율 데이터까지 삭제된다
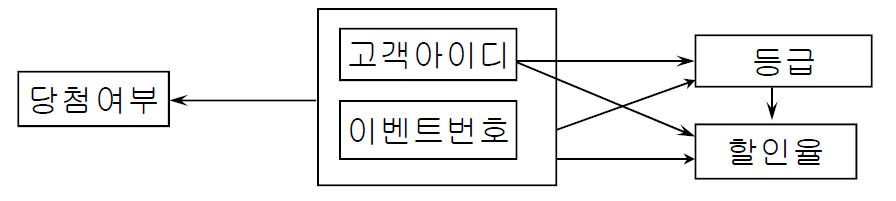
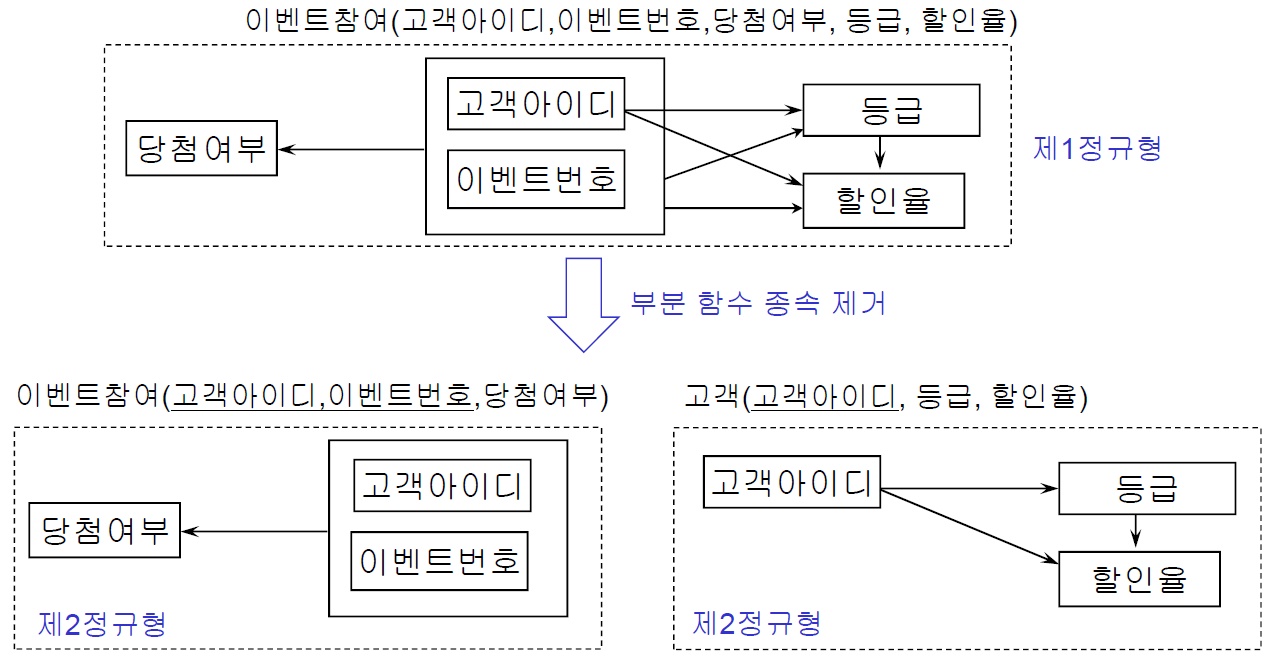
※ 완전 함수 종속 / 부분 함수 종속
- 복합 속성 X에 대하여 X -> Y가 성립할 시 { (고객 아이디, 이벤트 번호) -> 당첨 여부 }
- 완전 함수 종속 : X` ⊂ X이고, 속성 X`이 결정자인 함수 종속 관계가 존재하지 않음
- 부분 함수 종속 : X` ⊂ X이고, 속성 X`이 결정자인 함수 종속 관계가 존재함
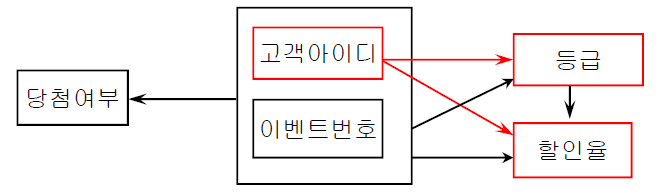
-> 복합 속성 (고객 아이디, 이벤트 번호) 중 고객 아이디가 결정자인 함수 종속 관계가 존재
※ 1NF 이상 원인과 해결
- 1NF 이상의 원인
- 기본키에 부분 함수 종속된 속성이 존재
- 1NF 이상의 해결
- 릴레이션 분해 (부분 함수 종속 제거)
2. 제2 정규형 (2NF)
- 제1 정규형(1NF) + 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속
- 기본키가 2개 이상의 속성으로 구성되었을 경우에만 1NF -> 2NF 만족하는지 고려
- 기본키가 1개일 경우, 1NF를 만족하면 자동적으로 2NF도 만족함
※ Example
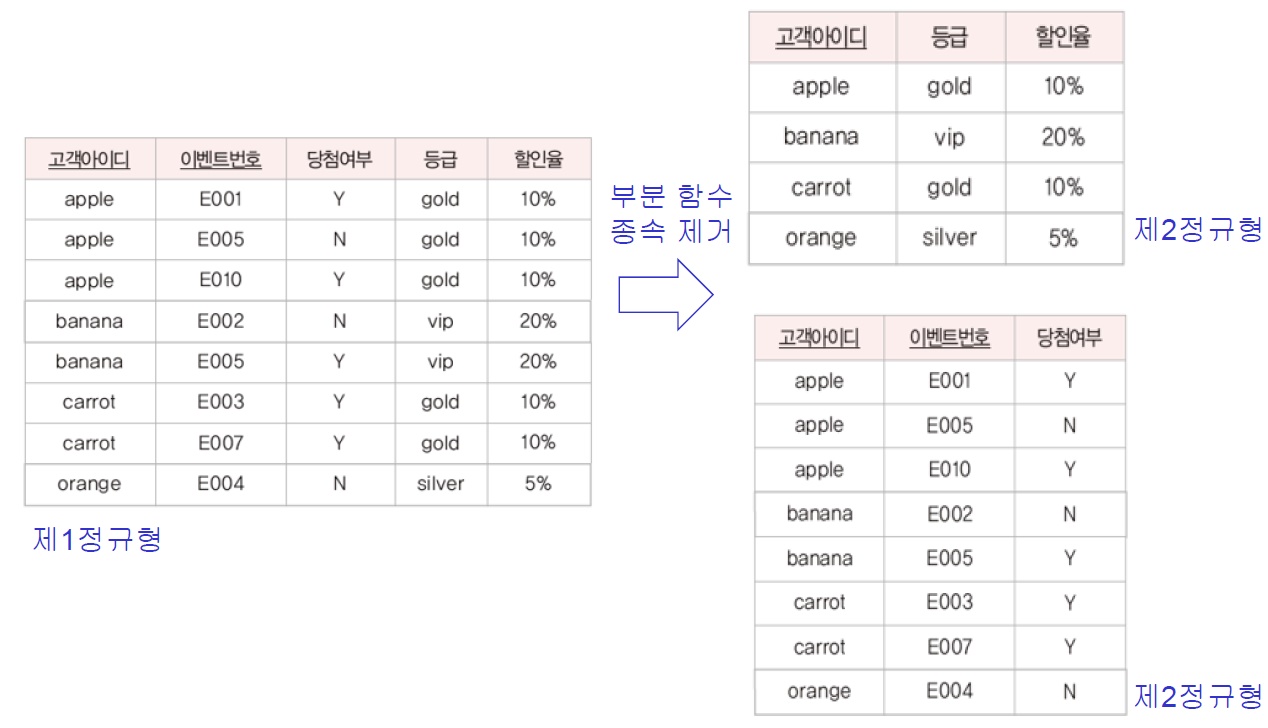
- 이상 현상
- 삽입 이상 : 할인율 1%인 bronze 등급이 새로 생길 시, '고객 아이디'에 가짜 값을 넣어야 삽입 가능
- 수정 이상 : gold 등급 할인율이 15%로 변경될 시, 일부 투플만 수정 (데이터 불일치 문제 발생)
- 삭제 이상 : 'banana' 고객이 탈퇴할 시, vip 등급 할인율 정보가 삭제된다 -> 고객 탈퇴와 관련 없는 등급, 할인율 데이터까지 삭제된다
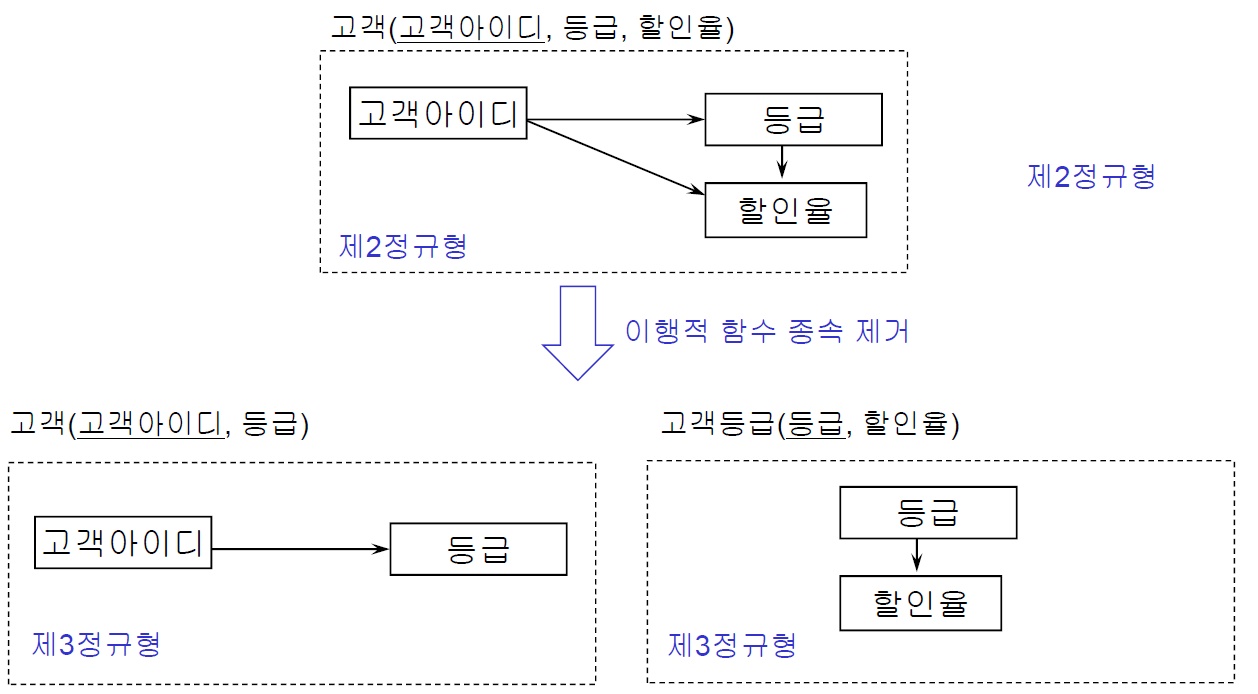
※ 이행적 함수 종속 (Transitive Functional Dependency)
- 한 릴레이션의 속성 A, B, C가 주어졌을 때 속성 C가 이행적으로 A에 종속한다(A -> C)는 것의 필요충분조건은 A → B ∧(AND) B→C 가 성립하는 것이다
- A가 릴레이션의 기본키라면 기본키의 정의에 따라 A→B와 A→C가 성립한다. 만일 C가 A 외에 B에도 함수적으로 종속한다면, C는 A에 직접 함수적으로 종속하면서 B를 거쳐서 A에 이행적으로 종속한다
- 결론적으로 A→B, B→C 이란 종속 관계가 있을 경우, A→C가 성립될 때 이행적 함수 종속이라고 한다
※ 2NF 이상 원인과 해결
- 2NF 이상의 원인
- 기본키가 아닌 속성들이 기본키에 이행적 함수 종속
- 2NF 이상의 해결
- 릴레이션 분해 (이행적 함수 종속 제거)
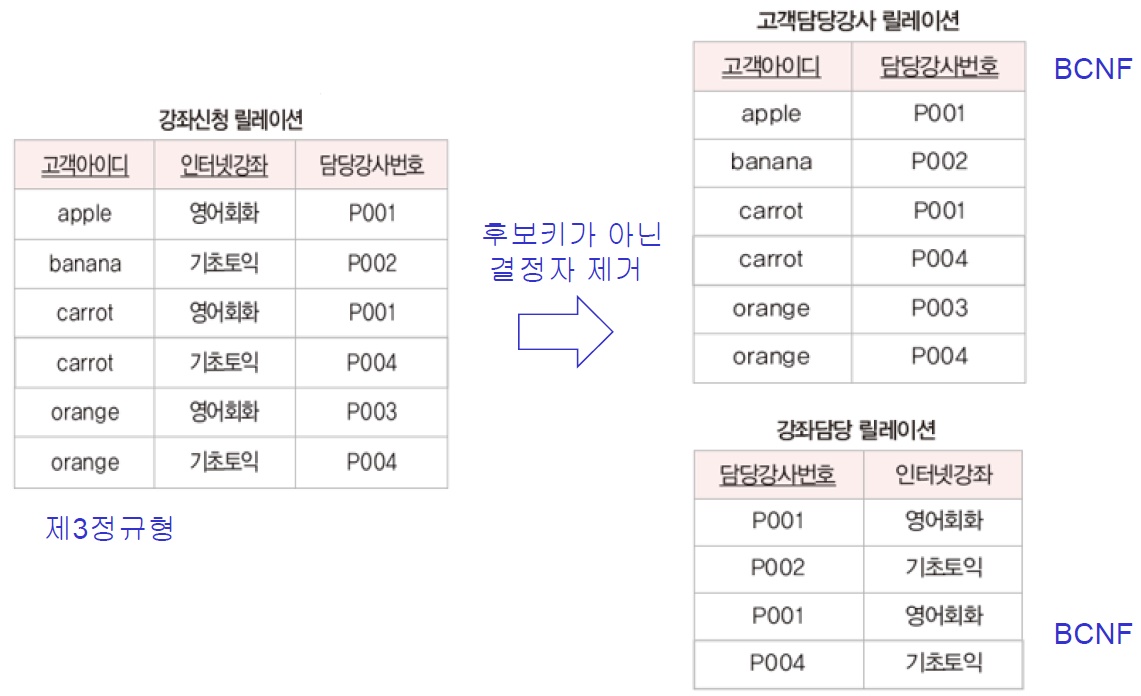
3. 제3 정규형 (3NF)
- 제2 정규형(2NF) + 기본키가 아닌 모든 속성들이 기본키에 이행적 함수 종속되지 않음
※ Example

- 강좌 신청 (고객 아이디, 인터넷 강좌, 담당 강사 번호)
- 후보키 : (고객 아이디, 인터넷 강좌) / (고객 아이디, 담당 강사 번호)
- 기본키 : (고객 아이디, 인터넷 강좌)
- 함수 종속 : (고객 아이디, 인터넷 강좌) -> 담당 강사 번호 / 담당강사번호 -> 인터넷 강좌
- 1NF : 모든 속성이 원자 값으로 구성
- 2NF : 1NF + 기본키가 아닌 속성인 담당 강사 번호가 기본키에 완전 함수 종속
- 3NF : 2NF + 이행적 함수 종속 없음
- 이상 현상
- 삽입 이상 : 신규로 P005 감사가 중급 토익을 담당 -> '고객 아이디'에 가짜 값을 넣어야 삽입 가능
- 수정 이상 : P004 강사의 강의가 중급 토익으로 변경 -> 일부 투플만 수정 (데이터 불일치 문제 발생)
- 삭제 이상 : 'banana'고객이 강좌 신청 취소할 시, P002 강사 정보도 삭제 -> 고객의 강사 취소와 관련 없는 담당 강사 번호 데이터까지 삭제
※ 3NF 이상 원인과 해결
- 3NF 이상의 원인
- '담당 강사 번호'가 결정자이긴 하지만 후보키가 아니다
- 3NF 이상의 해결
- 릴레이션 분해 (모든 결정자가 후보키가 되도록 분해)

4. 보이스/코드 정규형 (BCNF)
- 3NF + 릴레이션 R의 모든 결정자가 후보키
- 강한 제3 정규형 (strong 3NF)라고도 한다
※ Example
정규화 과정 정리

반정규화 (Denormalization)
- 정규화된 테이블을 비정규화 상태로 변경
- 성능 개선을 목적으로 데이터 중복으로 허용
- DB의 완벽한 구조 설계를 포기하고 데이터의 무결성을 떨어트리는 대신 관계형 DB의 읽기 성능 향상을 위한 설계
반정규화의 장·단점
- 장점
- 빠른 데이터 조회 (조인 비용이 줄어듦)
- 데이터 조회 쿼리가 간단해짐 (버그 발생 가능성이 줄어듦)
- 단점
- 데이터 갱신이나 삽입 비용이 높음
- 데이터 갱신 or 삽입 코드 작성하기가 어려워짐
- 데이터를 중복하여 저장하므로 더 많은 저장 공간이 필요
- 데이터 일관성이 깨짐
- 데이터의 정확성(무결성)이 떨어짐
- 읽기(조회) 속도는 빨라지지만 쓰기(삽입, 수정, 삭제) 속도는 느려진다
- 저장공간의 효율이 떨어진다
- 유지보수가 어렵다
반정규화 대상
- 자주 사용하는 테이블에 액세스 하는 프로세스의 수가 가장 많고, 항상 일정한 범위만 조회하는 경우
- 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우, 성능 상 이슈가 있을 경우
- 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우